RocketMQ 为什么性能不如 Kafka?
RocketMQ 为什么性能不如 Kafka?
在上篇文章《rocketmq 是什么》中,我们了解到 RocketMQ 的架构其实参考了 kafka 的设计思想,同时又在 kafka 的基础上做了一些调整。
看起来,RocketMQ 好像各方面都比 kafka 更能打。

但 kafka 却一直没被淘汰,说明 RocketMQ 必然是有着不如 kafka 的地方。
是啥呢?
性能,严格来说是吞吐量。阿里中间件团队对它们做过压测,同样条件下,kafka 比 RocketMQ 快 50%左右。但即使这样,RocketMQ 依然能每秒处理 10w 量级的数据,依旧非常能打。
你不能说 RocketMQ 弱,只能说 Kafka 性能太强了。
不过这就很奇怪了,为什么 RocketMQ 参考了 kafka 的架构,却不能跟 kafka 保持一样的性能呢?
在回答这个问题之前,我们来聊下什么是零拷贝。
零拷贝是什么
我们知道,消息队列的消息为了防止进程崩溃后丢失,一般不会放内存里,而是放磁盘上。
那么问题就来了,消息从消息队列的磁盘,发送到消费者,过程是怎么样的呢?
消息的发送过程
操作系统分为用户空间和内核空间。
程序处于用户空间,而磁盘属于硬件,操作系统本质上是程序和硬件设备的一个中间层。程序需要通过操作系统去调用硬件能力。
如果用户想要将数据从磁盘发送到网络。那么就会发生下面这几件事:
程序会发起系统调用read(),尝试读取磁盘数据,
- 磁盘数据从设备拷贝到内核空间的缓冲区。
- 再从内核空间的缓冲区拷贝到用户空间。
程序再发起系统调用write(),将读到的数据发到网络:
- 数据从用户空间拷贝到 socket 发送缓冲区
- 再从 socket 发送缓冲区拷贝到网卡。
最终数据就会经过网络到达消费者。
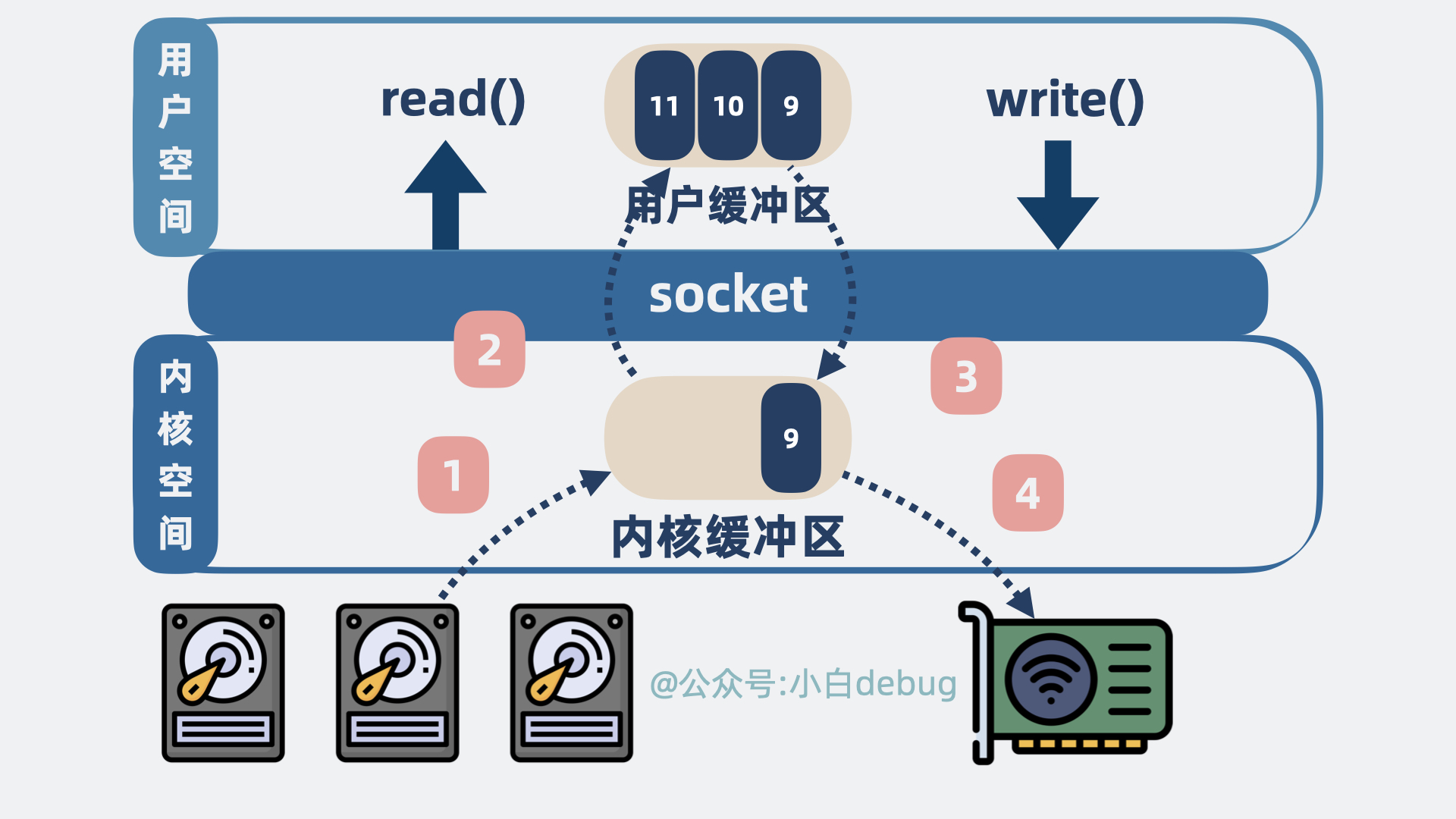
整个过程,本机内发生了 2 次系统调用,对应 4 次用户空间和内核空间的切换,以及 4 次数据拷贝。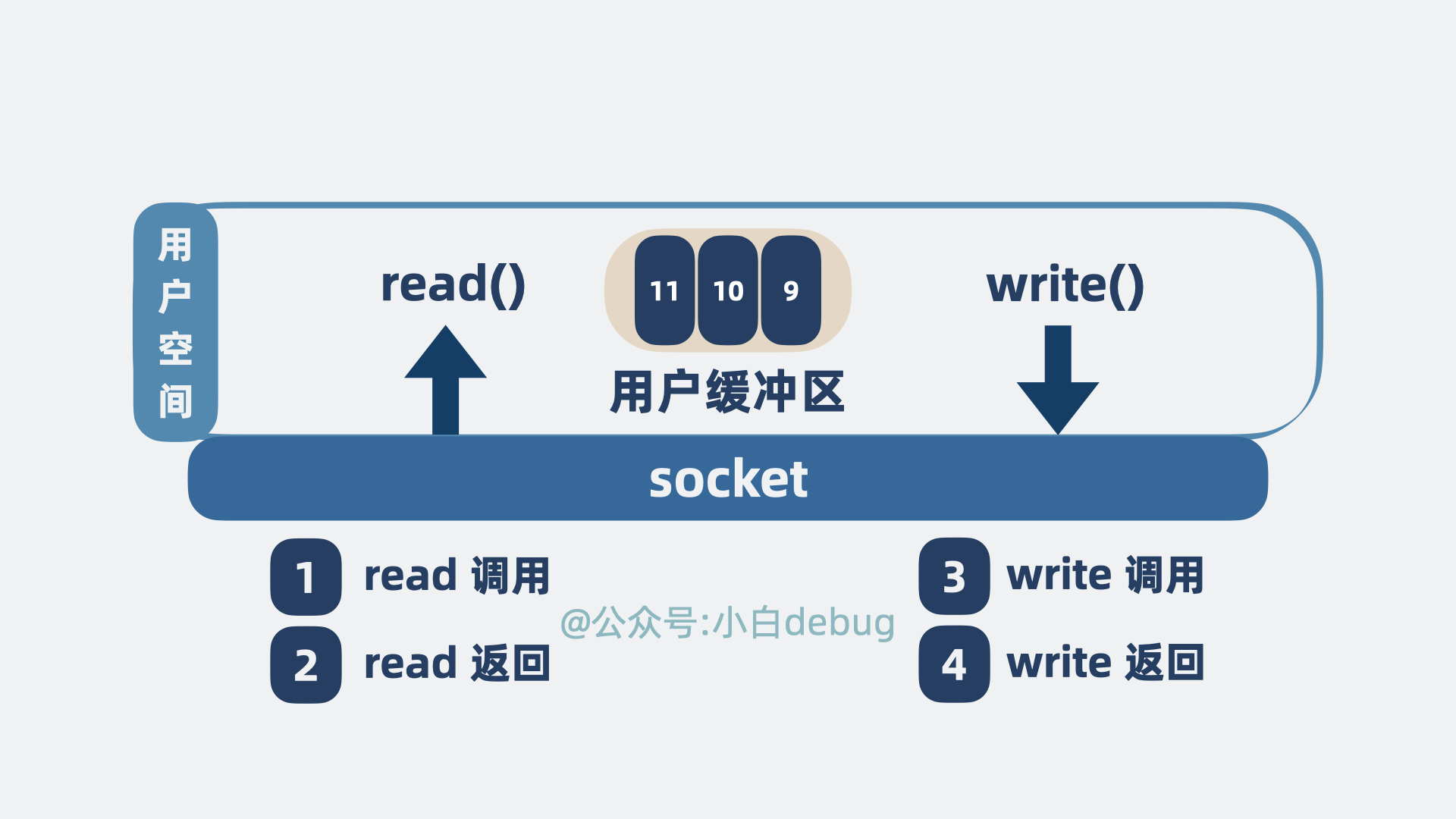
一顿操作猛如虎,结果就是同样一份数据来回拷贝。
有没有办法优化呢?
有,它就是零拷贝技术,常见的方案有两种,分别是 mmap 和 sendfile。我们来看下它们是什么。
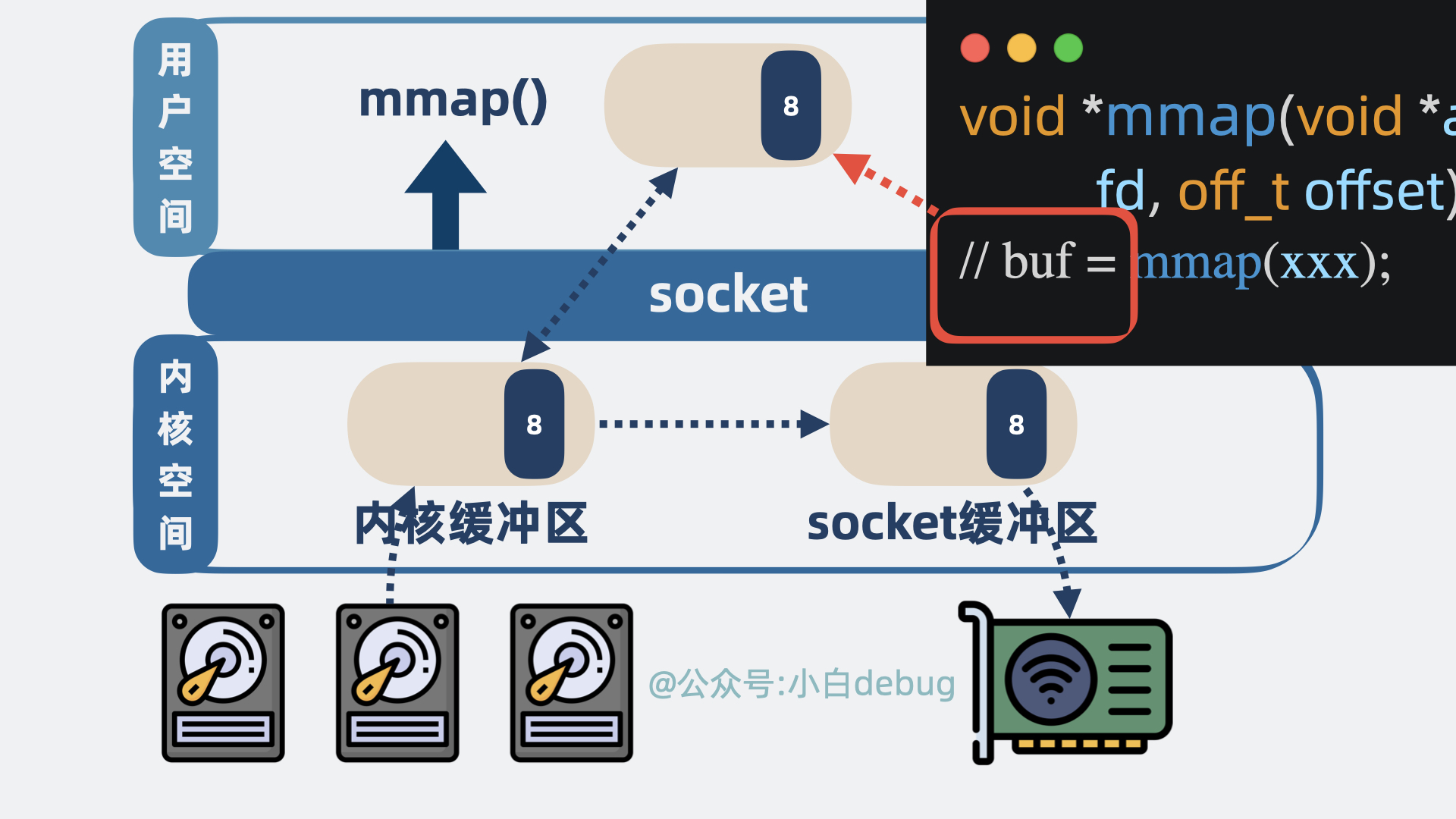
mmap 是什么
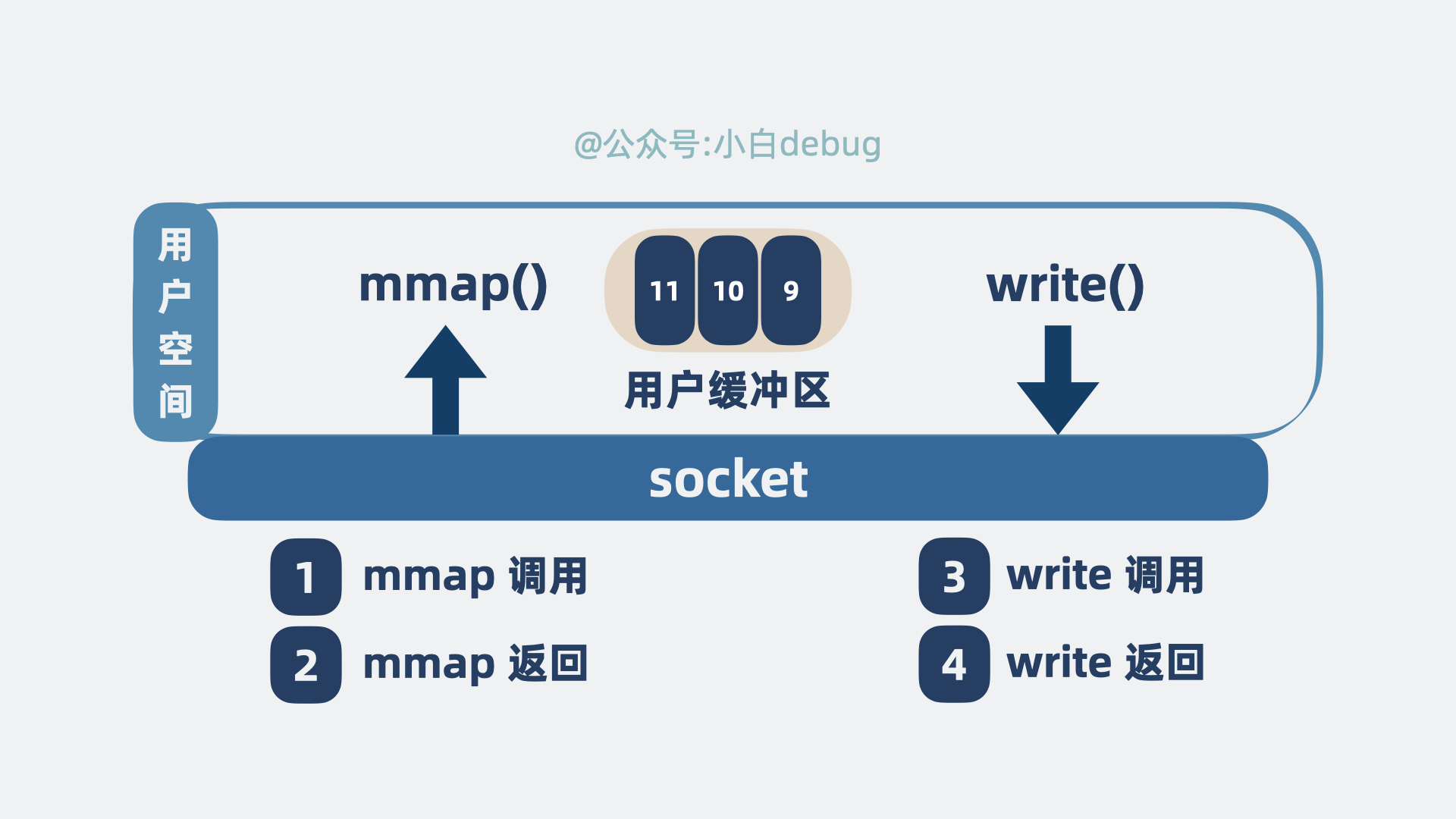
mmap 是操作系统内核提供的一个方法,可以将内核空间的缓冲区映射到用户空间。
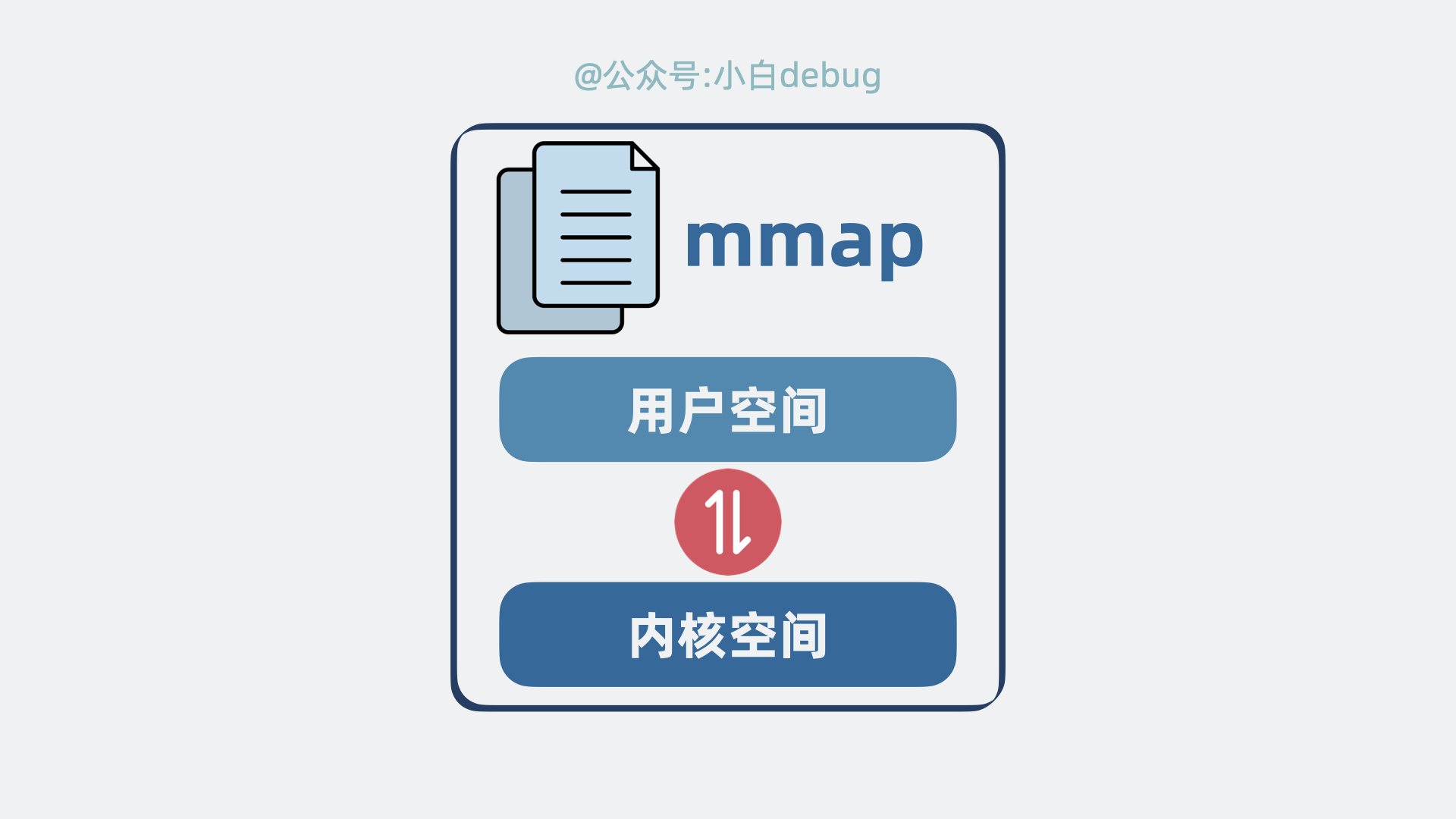
用了它,整个发送流程就有了一些变化。
程序发起系统调用mmap(),尝试读取磁盘数据,具体情况如下:
- 磁盘数据从设备拷贝到内核空间的缓冲区。
- 内核空间的缓冲区映射到用户空间,这里不需要拷贝。
程序再发起系统调用write(),将读到的数据发到网络:
- 数据从内核空间缓冲区拷贝到 socket 发送缓冲区。
- 再从 socket 发送缓冲区拷贝到网卡。
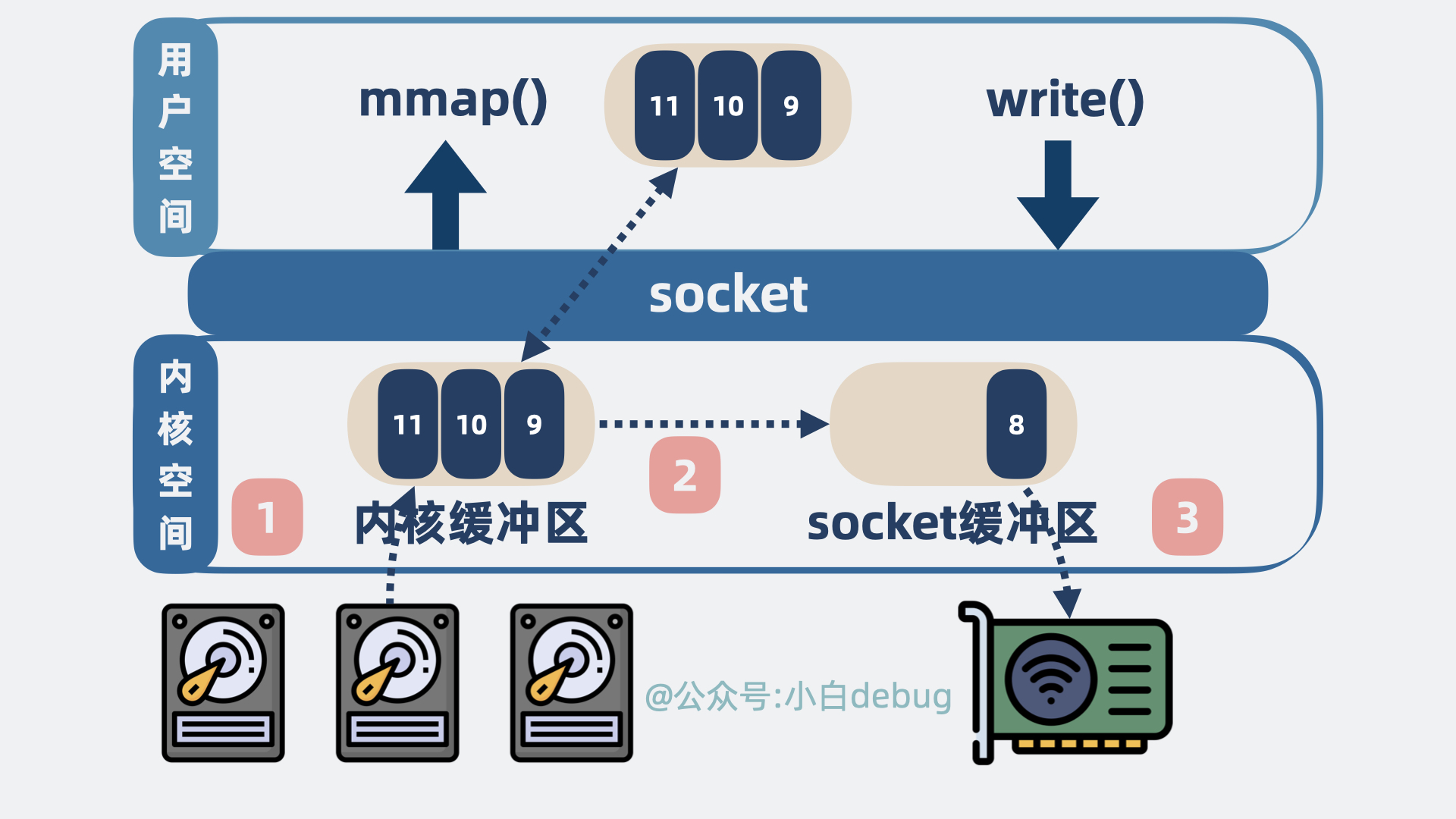
整个过程,发生了 2 次系统调用,对应 4 次用户空间和内核空间的切换,以及 3 次数据拷贝,对比之前,省下一次内核空间到用户空间的拷贝。
看到这里大家估计也蒙了,不是说零拷贝吗?怎么还有 3 次拷贝。
mmap 作为一种零拷贝技术,指的是用户空间到内核空间这个过程不需要拷贝,而不是指数据从磁盘到发送到网卡这个过程零拷贝。
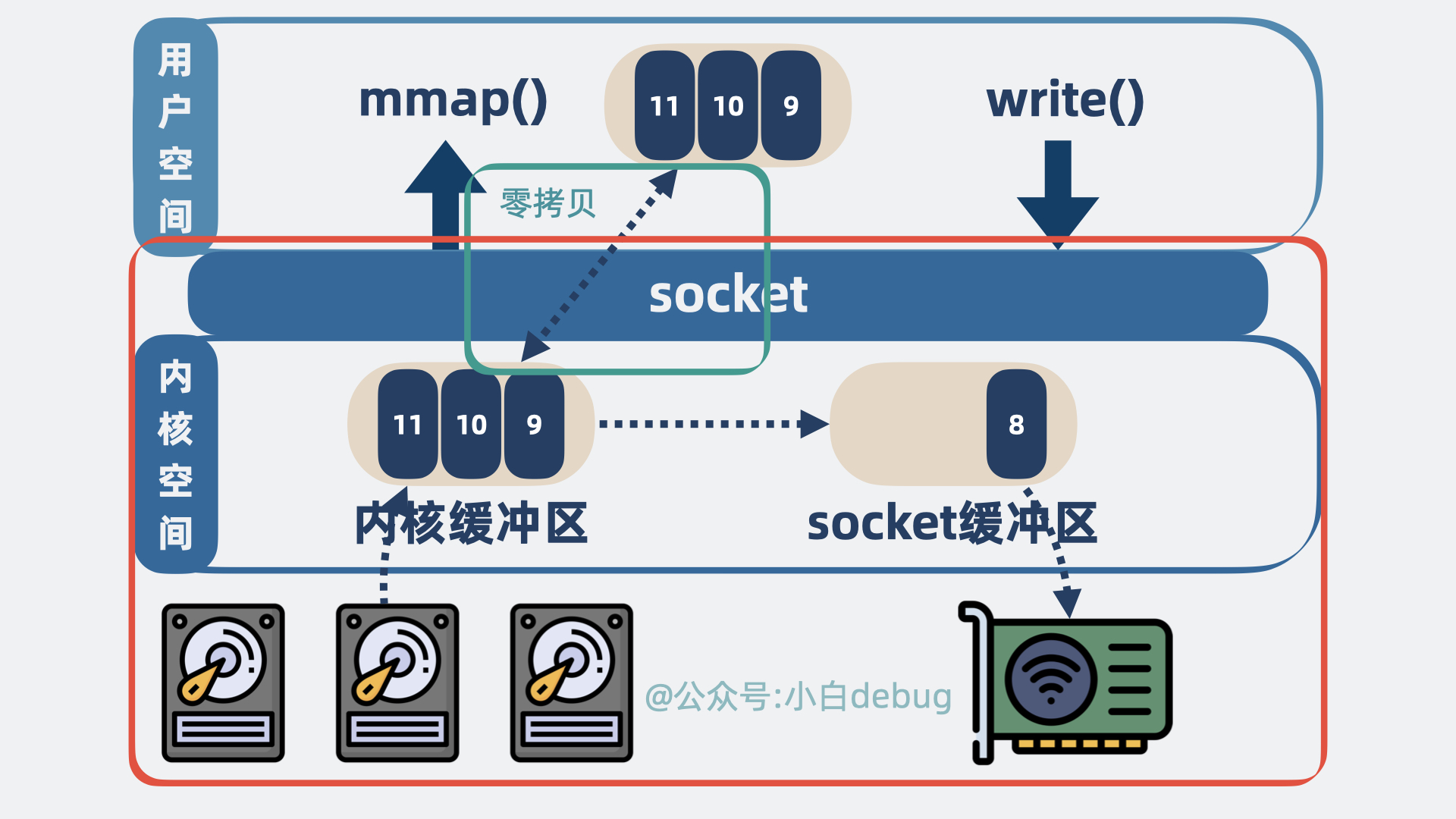
确实省了一点,但不多。有没有更彻底的零拷贝?
有,用 sendfile.
sendfile 是什么
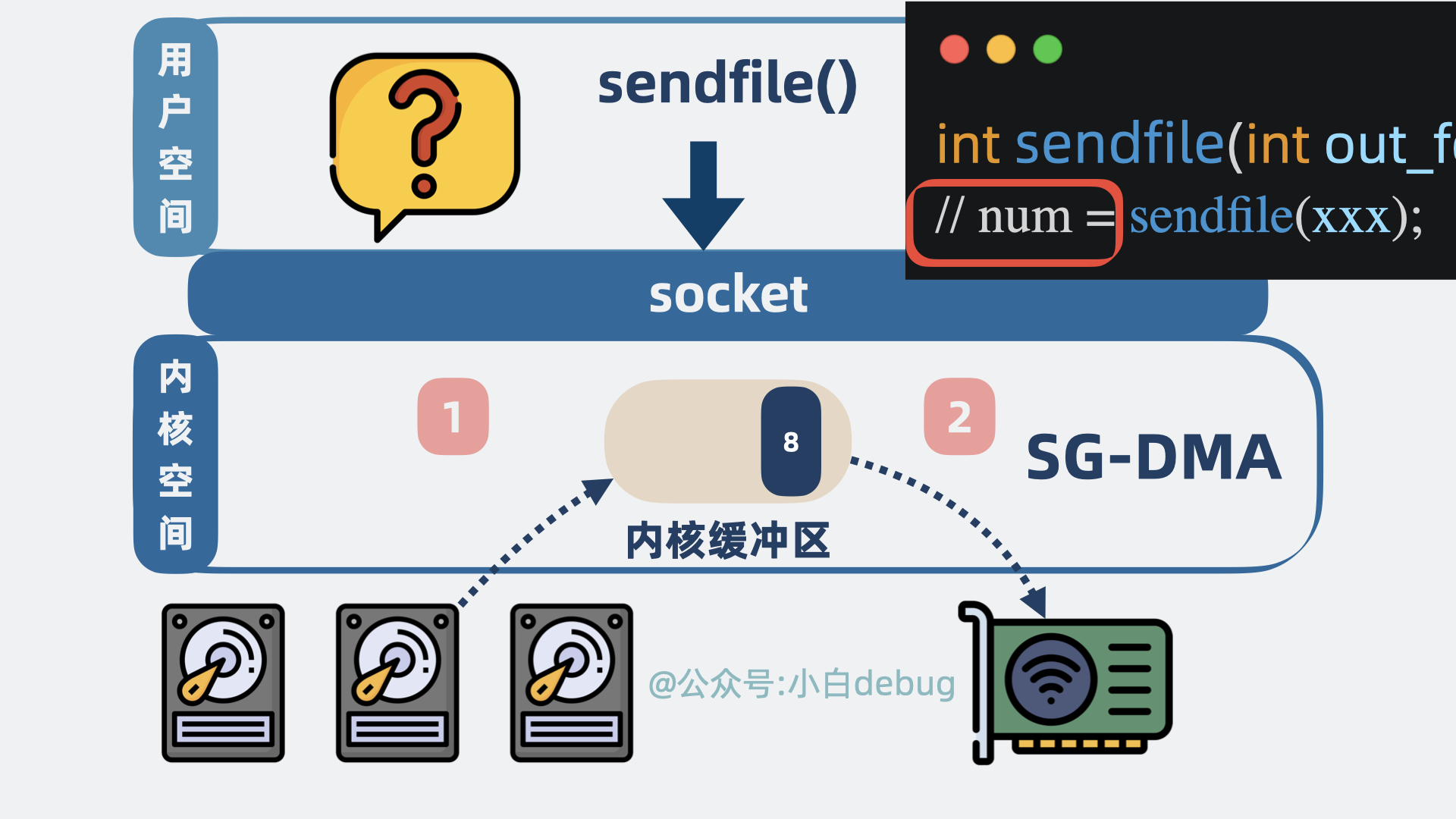
sendfile,也是内核提供的一个方法,从名字可以看出,就是用来发送文件数据的。
程序发起系统调用sendfile(),内核会尝试读取磁盘数据然后发送,具体情况如下:
- 磁盘数据从设备拷贝到内核空间的缓冲区。
- 内核空间缓冲区里的数据可以直接拷贝到网卡。
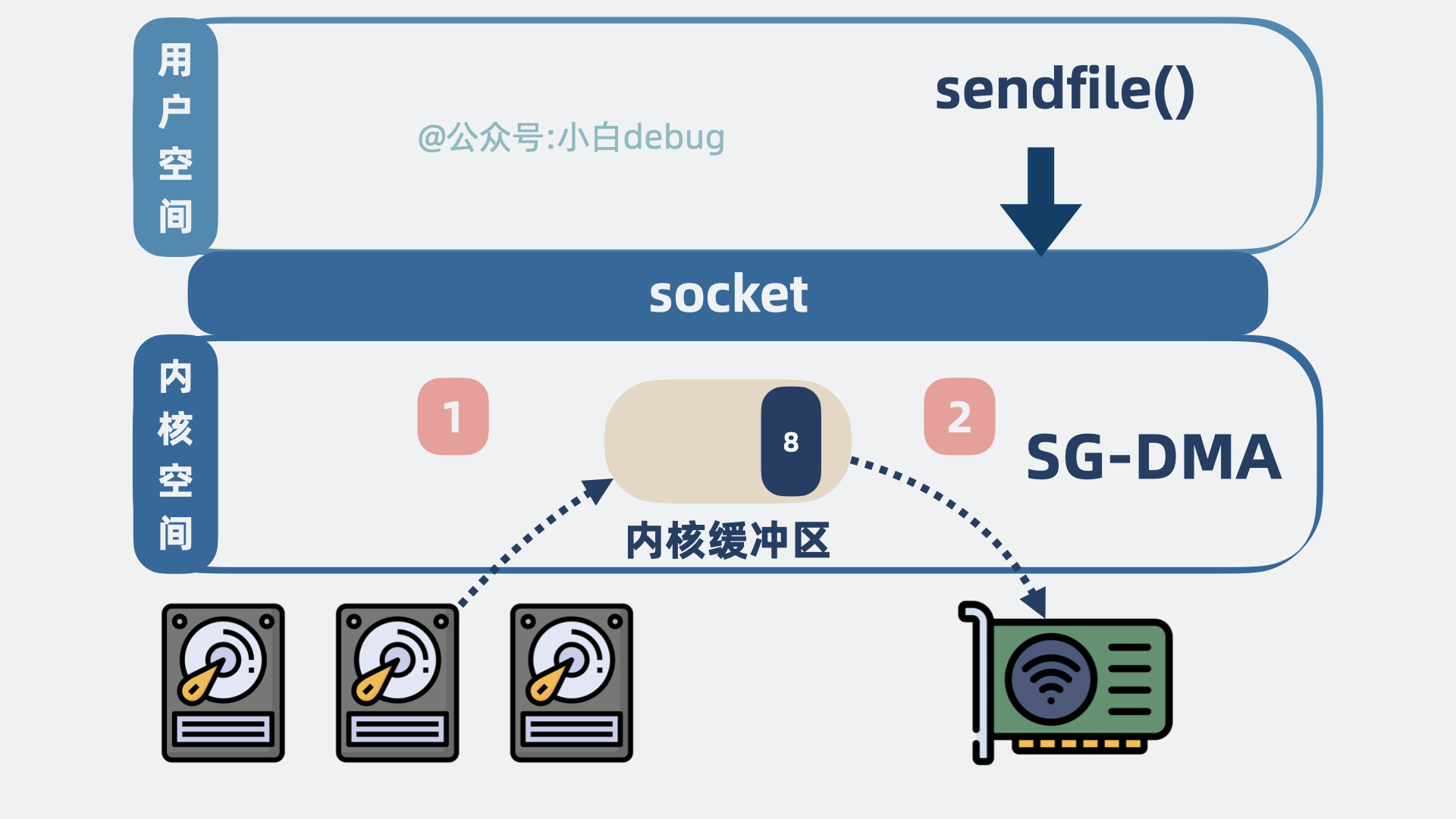
整个过程,发生了 1 次系统调用,对应 2 次用户空间和内核空间的切换,以及 2 次数据拷贝。
这时候问题很多的小明就有意见了,说好的零拷贝怎么还有 2 次拷贝?
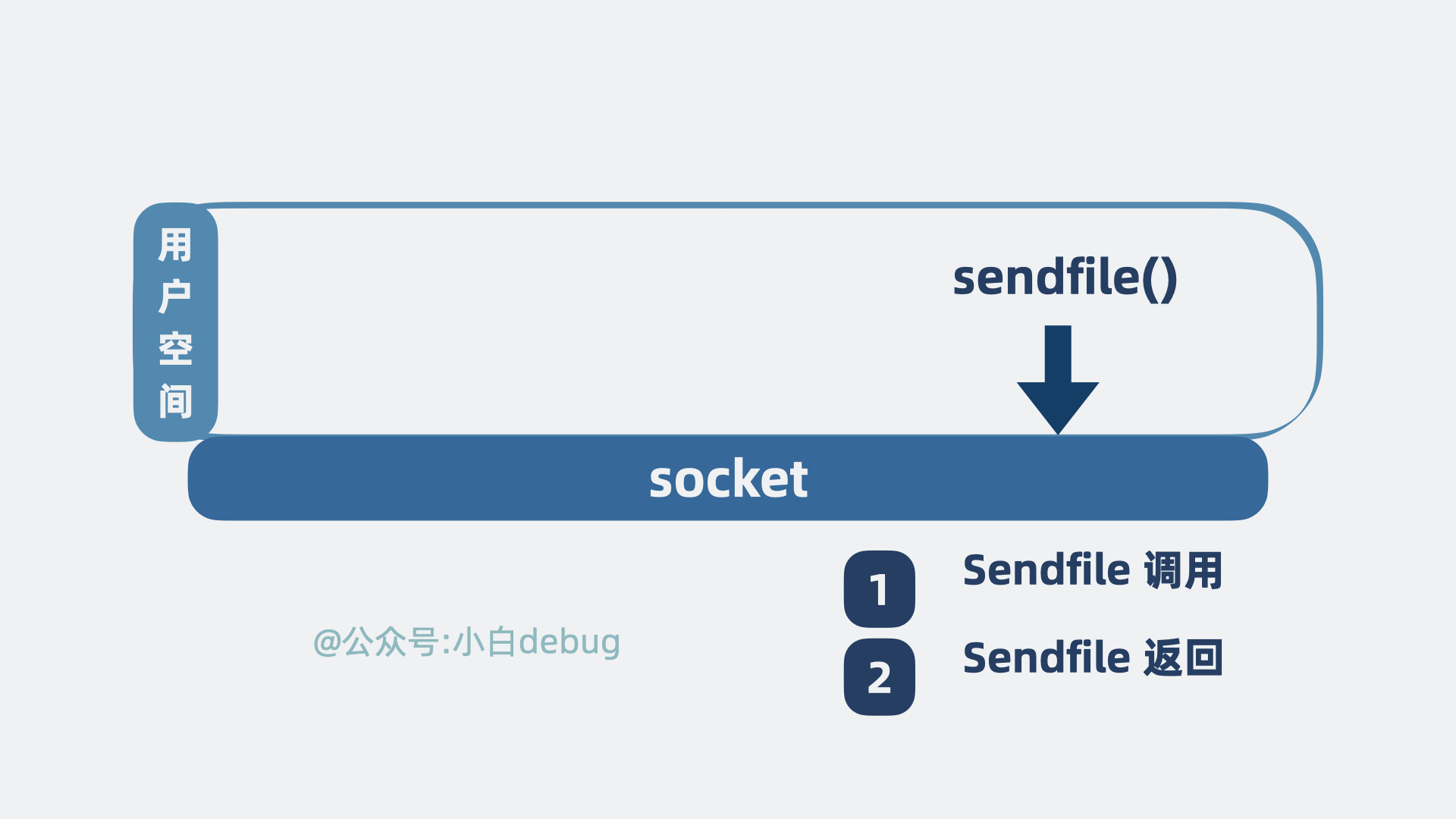
其实,这里的零拷贝指的是零 CPU拷贝。
也就是说 sendfile 场景下,需要的两次拷贝,都不是 CPU 直接参与的拷贝,而是其他硬件设备技术做的拷贝,不耽误我们 CPU 跑程序。
kafka 为什么性能比 RocketMQ 好
聊完两种零拷贝技术,我们回过头来看下 kafka 为什么性能比 RocketMQ 好。
这是因为 RocketMQ 使用的是 mmap 零拷贝技术,而 kafka 使用的是 sendfile。kafka 以更少的拷贝次数以及系统内核切换次数,获得了更高的性能。
但问题又来了,为什么 RocketMQ 不使用 sendfile?参考 kafka 抄个作业也不难啊?
我们来看下 sendfile 函数长啥样。
ssize_t sendfile(int out_fd, int in_fd, off_t* offset, size_t count);
// num = sendfile(xxx);
再来看下 mmap 函数长啥样。
void *mmap(void *addr, size_t length, int prot, int flags,
int fd, off_t offset);
// buf = mmap(xxx)
注释里写的是两个函数的用法,mmap 返回的是数据的具体内容,应用层能获取到消息内容并进行一些逻辑处理。
 而
而 sendfile 返回的则是发送成功了几个字节数,具体发了什么内容,应用层根本不知道。
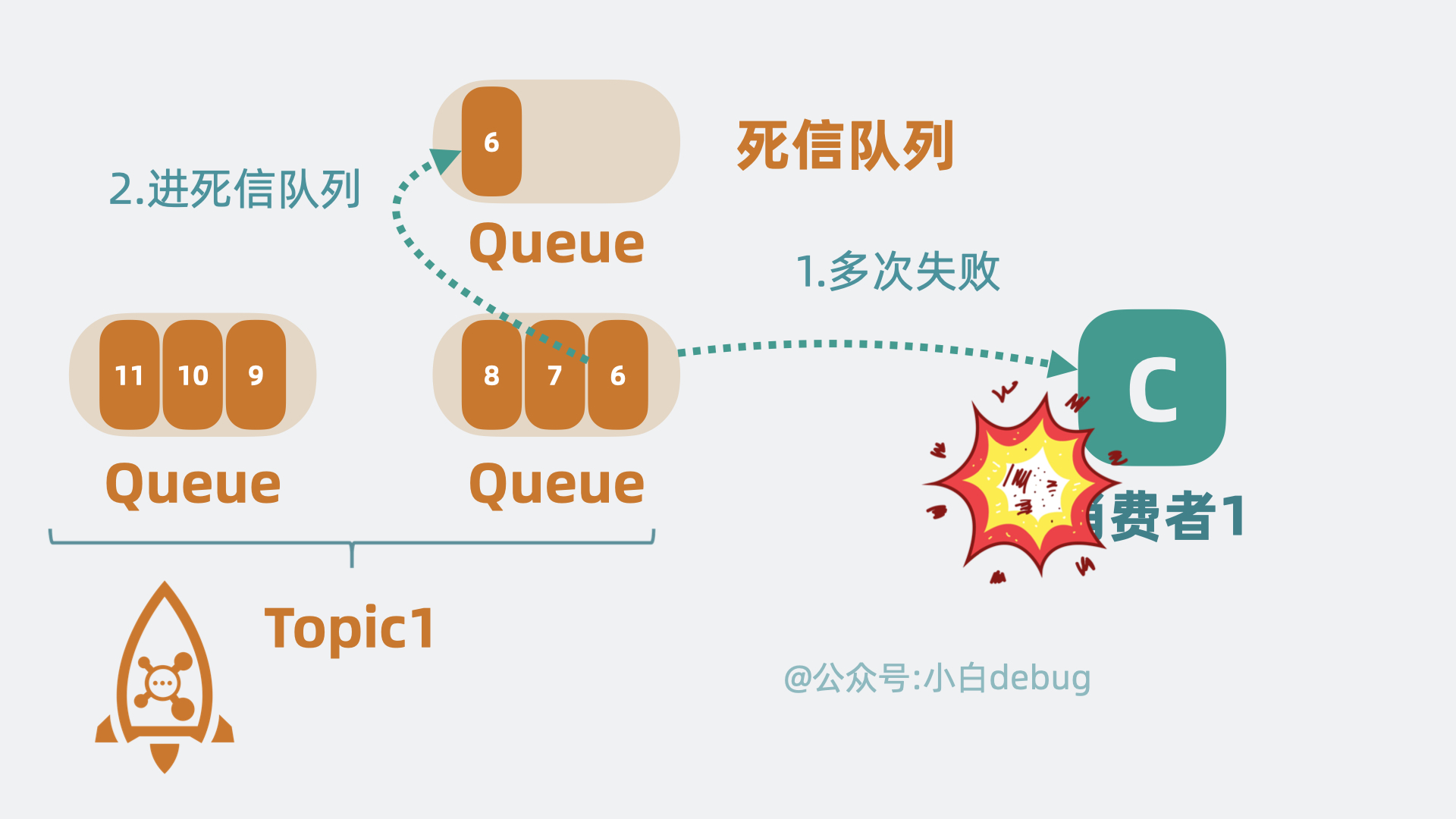
而 RocketMQ 的一些功能,却需要了解具体这个消息内容,方便二次投递等,比如将消费失败的消息重新投递到死信队列中,如果 RocketMQ 使用 sendfile,那根本没机会获取到消息内容长什么样子,也就没办法实现一些好用的功能了。
而 kafka 却没有这些功能特性,追求极致性能,正好可以使用 sendfile。
除了零拷贝以外,kafka 高性能的原因还有很多,比如什么批处理,数据压缩啥的,但那些优化手段 rocketMQ 也都能借鉴一波,唯独这个零拷贝,那是毫无办法。

所以还是那句话,没有一种架构是完美的,一种架构往往用于适配某些场景,你很难做到既要又要还要。
当场景不同,我们就需要做一些定制化改造,通过牺牲一部分能力去换取另一部分能力。
做架构,做到最后都是在做折中。
是不是感觉升华了。
kafka 和 RocketMQ 怎么选?
这时候大家估计还是想知道 kafka 和 RocketMQ 到底该怎么选,用哪个。
官方点的回答是"这个要看场景的"。说了等于没说。
这不是我的风格。
我的标准只有一个,如果是大数据场景,比如你能频繁听到 spark,flink 这些关键词的时候,那就用 kafka。
除此之外,如果公司组件支持,尽量用 RocketMQ。
现在大家通了吗?
总结
- RocketMQ 和 kafka 相比,在架构上做了减法,在功能上做了加法
- 跟 kafka 的架构相比,RocketMQ 简化了协调节点和分区以及备份模型。同时增强了消息过滤、消息回溯和事务能力,加入了延迟队列,死信队列等新特性。
- 凡事皆有代价,RocketMQ 牺牲了一部分性能,换取了比 kafka 更强大的功能特性。