用了TCP协议,就一定不会丢包吗?
文章持续更新,可以微信搜一搜「小白 debug」第一时间阅读,回复【面试】获面试题集。本文已经收录在 GitHub https://github.com/xiaobaiTech/golangFamily , 有大厂面试完整考点和成长路线,欢迎 Star。
表面上我是个技术博主。
但没想到今天成了个情感博主。
我是没想到有一天,我会通过技术知识,来挽救粉丝即将破碎的感情。
掏心窝子的说。这件事情多少是沾点功德无量了。
事情是这样的。
最近就有个读者加了我的绿皮聊天软件,女生,头像挺好看的,就在我以为她要我拉她进群发成人专升本广告的时候。
画风突然不对劲。
她说她男朋友也是个程序员,异地恋,也关注了我,天天研究什么TCP,UDP 网络。一研究就是一晚上,一晚上都不回她消息的那种。
话里有话,懂。
不出意外的出了意外,她发出了灵魂拷问
"你们程序员真的有那么忙吗?忙到连消息都不知道回。"
没想到上来就是一记直拳。
但是,这一拳,我接住了。

我很想告诉她"分了吧,下一题"。
但我不能。因为这样我就伤害了我的读者兄弟。
沉默了一下。

单核 cpu 都快转冒烟了,才颤颤巍巍在九宫格键盘上发出消息。
再回慢一点,我就感觉,我要对不起我这全日制本科学历了。
"其实,他已经回了你消息了,但你知道吗?网络是会丢包的。"
"我来帮他解释下,这个话题就要从数据包的发送流程聊起"
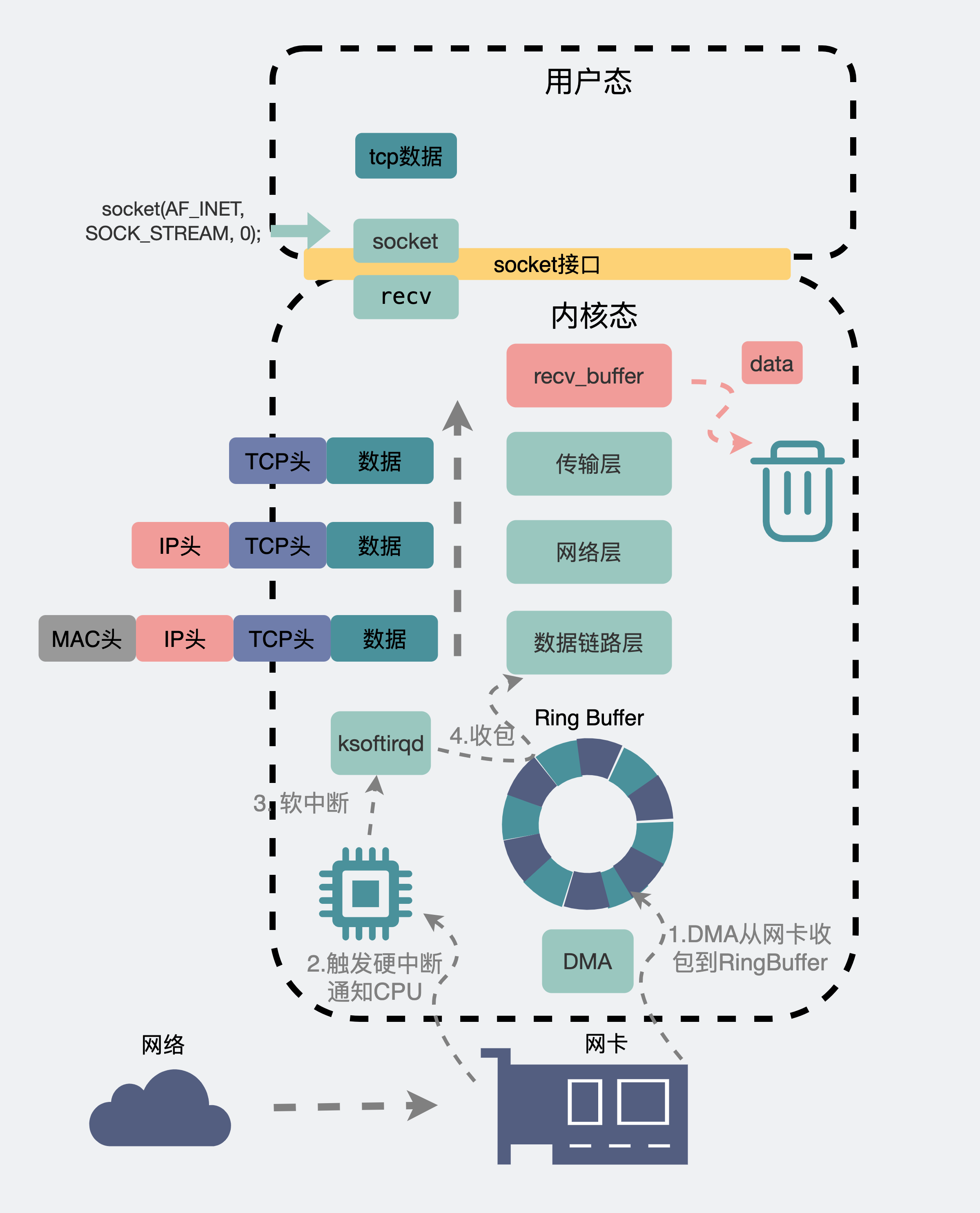
数据包的发送流程
首先,我们两个手机的绿皮聊天软件客户端,要通信,中间会通过它们家服务器。大概长这样。
但为了简化模型,我们把中间的服务器给省略掉,假设这是个端到端的通信。且为了保证消息的可靠性,我们盲猜它们之间用的是TCP 协议进行通信。

为了发送数据包,两端首先会通过三次握手,建立 TCP 连接。
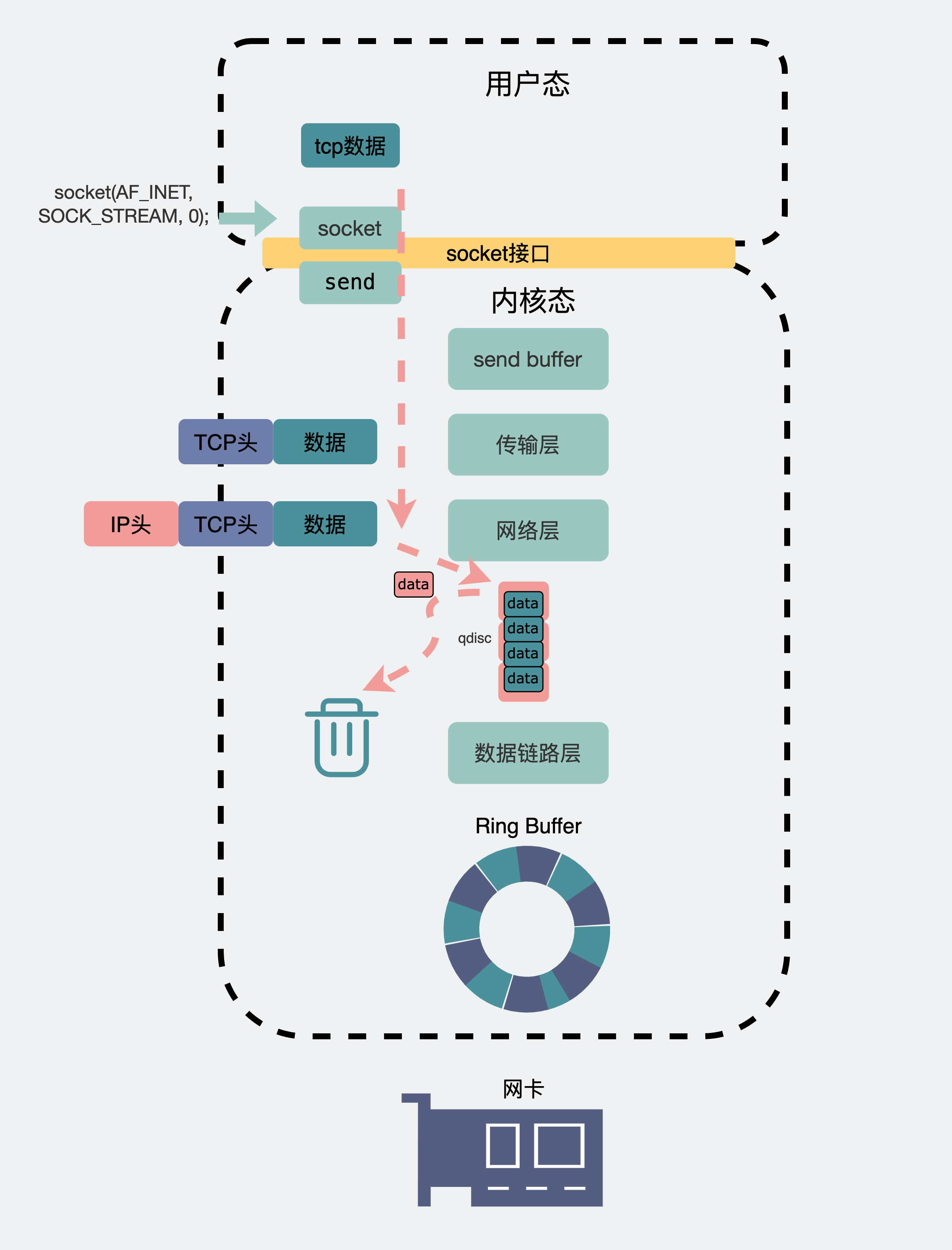
一个数据包,从聊天框里发出,消息会从聊天软件所在的用户空间拷贝到内核空间的发送缓冲区(send buffer),数据包就这样顺着传输层、网络层,进入到数据链路层,在这里数据包会经过流控(qdisc),再通过 RingBuffer 发到物理层的网卡。数据就这样顺着网卡发到了纷繁复杂的网络世界里。这里头数据会经过 n 多个路由器和交换机之间的跳转,最后到达目的机器的网卡处。
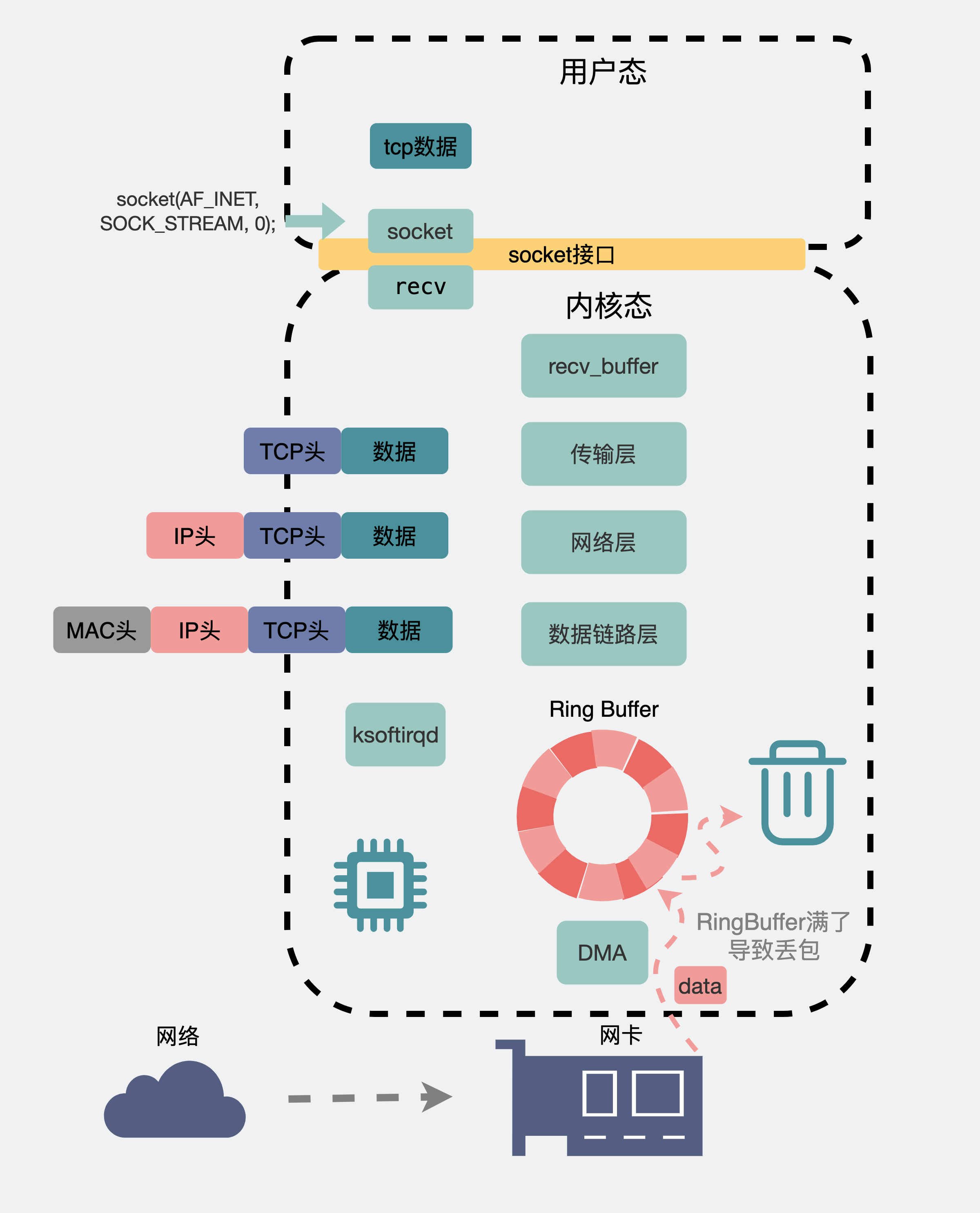
此时目的机器的网卡会通知DMA将数据包信息放到RingBuffer中,再触发一个硬中断给CPU,CPU触发软中断让ksoftirqd去RingBuffer收包,于是一个数据包就这样顺着物理层,数据链路层,网络层,传输层,最后从内核空间拷贝到用户空间里的聊天软件里。
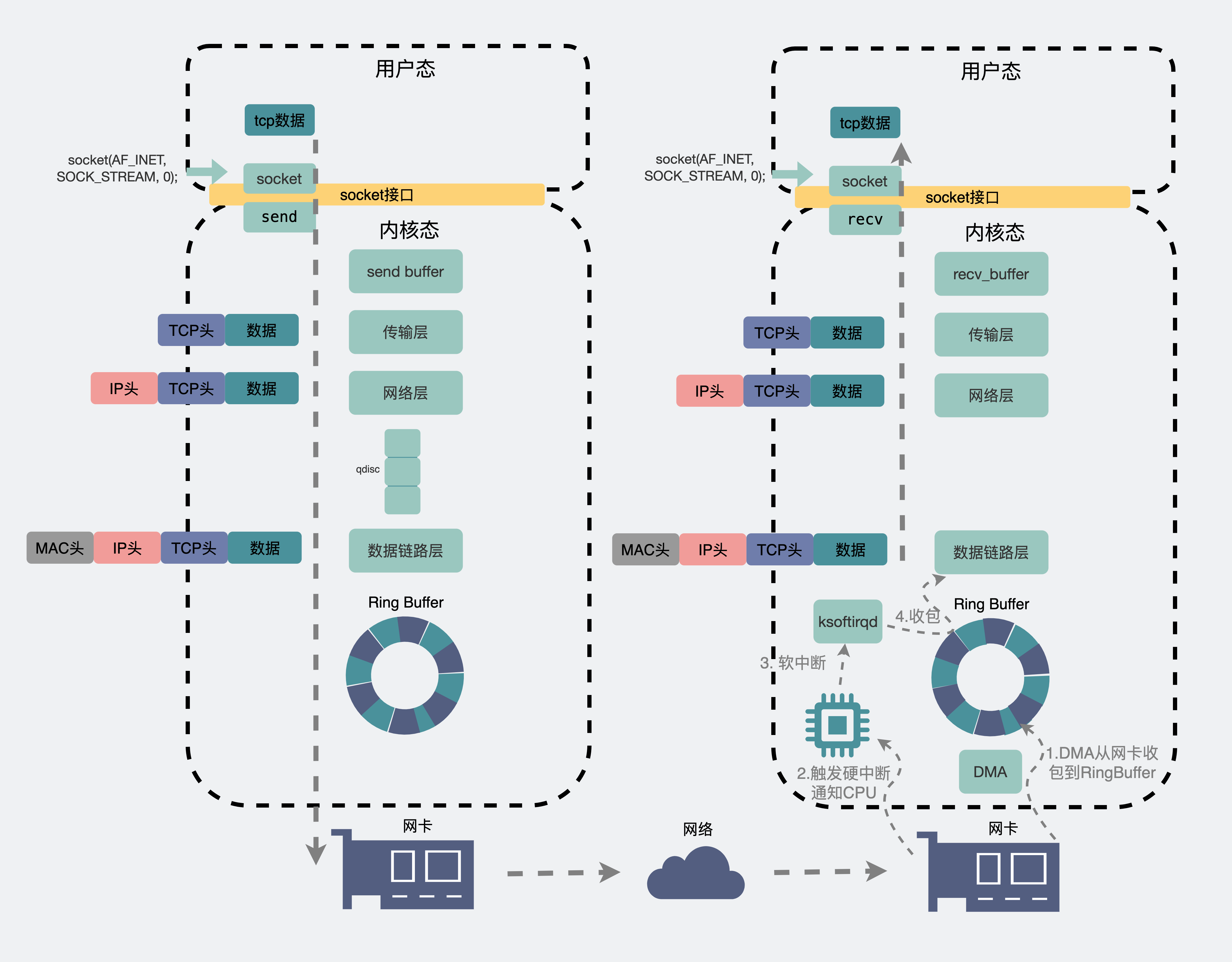
画了那么大一张图,只水了 200 字做解释,我多少是有些心痛的。
到这里,抛开一些细节,大家大概知道了一个数据包从发送到接收的宏观过程。
可以看到,这上面全是密密麻麻的名词。
整条链路下来,有不少地方可能会发生丢包。
但为了不让大家保持蹲姿太久影响身体健康,我这边只重点讲下几个常见容易发生丢包的场景。
建立连接时丢包
TCP 协议会通过三次握手建立连接。大概长下面这样。
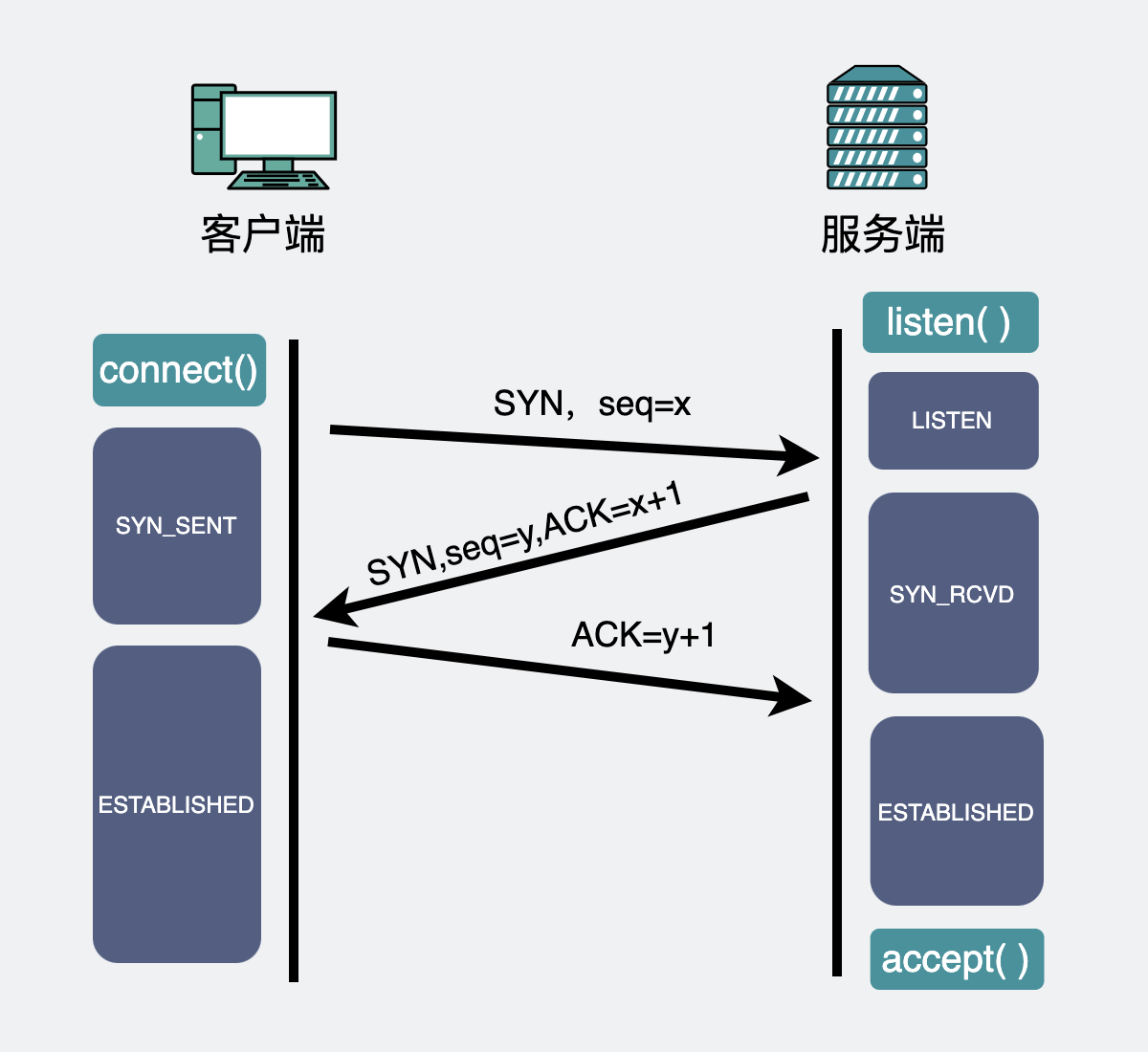
在服务端,第一次握手之后,会先建立个半连接,然后再发出第二次握手。这时候需要有个地方可以暂存这些半连接。这个地方就叫半连接队列。
如果之后第三次握手来了,半连接就会升级为全连接,然后暂存到另外一个叫全连接队列的地方,坐等程序执行accept()方法将其取走使用。
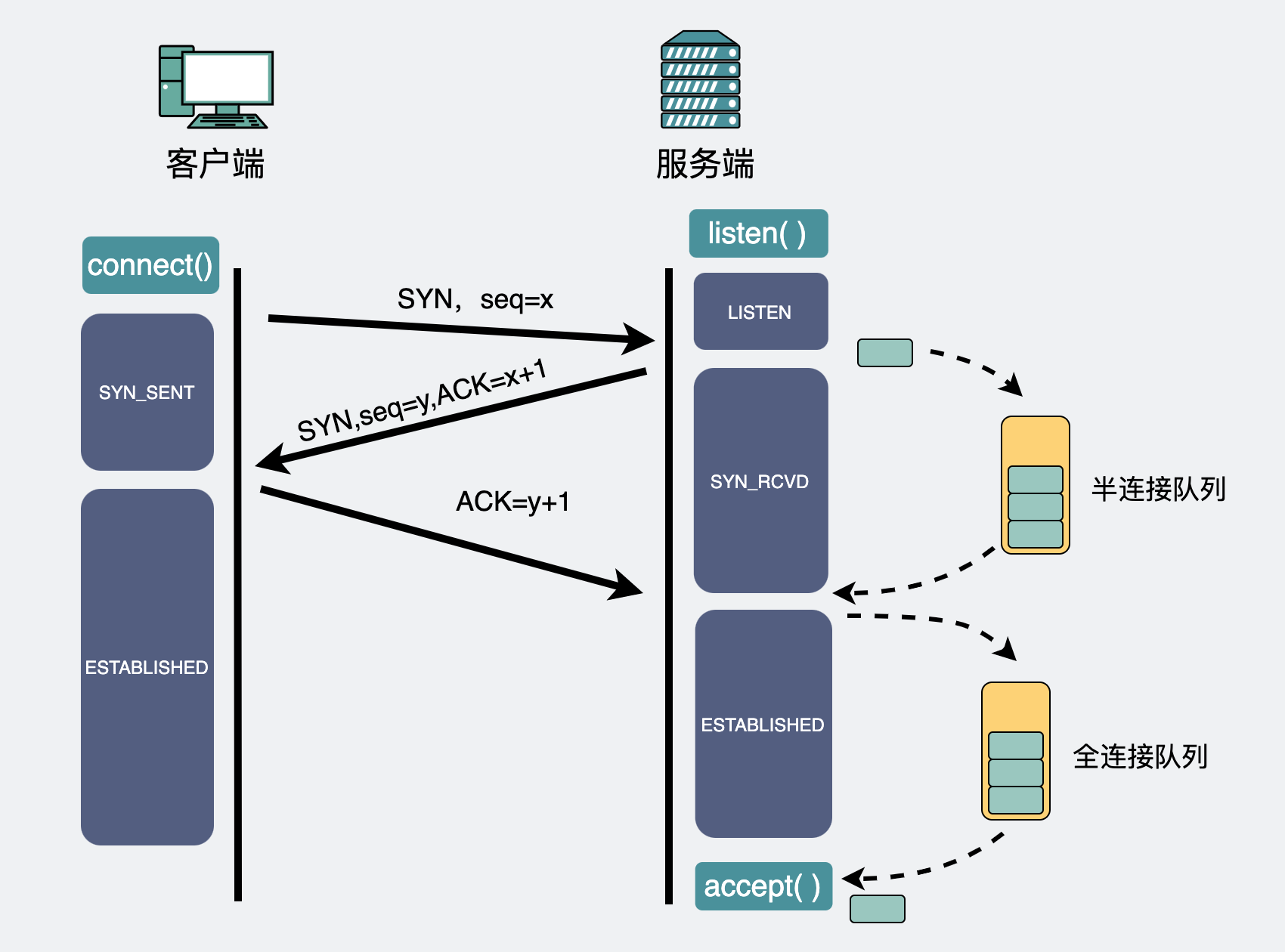
是队列就有长度,有长度就有可能会满,如果它们满了,那新来的包就会被丢弃。
可以通过下面的方式查看是否存在这种丢包行为。
# 全连接队列溢出次数
# netstat -s | grep overflowed
4343 times the listen queue of a socket overflowed
# 半连接队列溢出次数
# netstat -s | grep -i "SYNs to LISTEN sockets dropped"
109 times the listen queue of a socket overflowed
从现象来看就是连接建立失败。
这个话题在之前写的《没有 accept,能建立 TCP 连接吗?》有更详细的聊过,感兴趣的可以回去看下。
流量控制丢包
应用层能发网络数据包的软件有那么多,如果所有数据不加控制一股脑冲入到网卡,网卡会吃不消,那怎么办?让数据按一定的规则排个队依次处理,也就是所谓的qdisc(Queueing Disciplines,排队规则),这也是我们常说的流量控制机制。
排队,得先有个队列,而队列有个长度。
我们可以通过下面的ifconfig命令查看到,里面涉及到的txqueuelen后面的数字1000,其实就是流控队列的长度。
当发送数据过快,流控队列长度txqueuelen又不够大时,就容易出现丢包现象。
可以通过下面的ifconfig命令,查看 TX 下的 dropped 字段,当它大于 0 时,则有可能是发生了流控丢包。
# ifconfig eth0
eth0: flags=4163<UP,BROADCAST,RUNNING,MULTICAST> mtu 1500
inet 172.21.66.69 netmask 255.255.240.0 broadcast 172.21.79.255
inet6 fe80::216:3eff:fe25:269f prefixlen 64 scopeid 0x20<link>
ether 00:16:3e:25:26:9f txqueuelen 1000 (Ethernet)
RX packets 6962682 bytes 1119047079 (1.0 GiB)
RX errors 0 dropped 0 overruns 0 frame 0
TX packets 9688919 bytes 2072511384 (1.9 GiB)
TX errors 0 dropped 0 overruns 0 carrier 0 collisions 0
当遇到这种情况时,我们可以尝试修改下流控队列的长度。比如像下面这样将 eth0 网卡的流控队列长度从 1000 提升为 1500.
# ifconfig eth0 txqueuelen 1500
网卡丢包
网卡和它的驱动导致丢包的场景也比较常见,原因很多,比如网线质量差,接触不良。除此之外,我们来聊几个常见的场景。
RingBuffer 过小导致丢包
上面提到,在接收数据时,会将数据暂存到RingBuffer接收缓冲区中,然后等着内核触发软中断慢慢收走。如果这个缓冲区过小,而这时候发送的数据又过快,就有可能发生溢出,此时也会产生丢包。
我们可以通过下面的命令去查看是否发生过这样的事情。
# ifconfig
eth0: RX errors 0 dropped 0 overruns 0 frame 0
查看上面的overruns指标,它记录了由于RingBuffer长度不足导致的溢出次数。
当然,用ethtool命令也能查看。
# ethtool -S eth0|grep rx_queue_0_drops
但这里需要注意的是,因为一个网卡里是可以有多个 RingBuffer的,所以上面的rx_queue_0_drops里的 0 代表的是第 0 个 RingBuffer的丢包数,对于多队列的网卡,这个 0 还可以改成其他数字。但我的家庭条件不允许我看其他队列的丢包数,所以上面的命令对我来说是够用了。。。
当发现有这类型丢包的时候,可以通过下面的命令查看当前网卡的配置。
#ethtool -g eth0
Ring parameters for eth0:
Pre-set maximums:
RX: 4096
RX Mini: 0
RX Jumbo: 0
TX: 4096
Current hardware settings:
RX: 1024
RX Mini: 0
RX Jumbo: 0
TX: 1024
上面的输出内容,含义是RingBuffer 最大支持 4096 的长度,但现在实际只用了 1024。
想要修改这个长度可以执行ethtool -G eth1 rx 4096 tx 4096将发送和接收 RingBuffer 的长度都改为 4096。
RingBuffer增大之后,可以减少因为容量小而导致的丢包情况。
网卡性能不足
网卡作为硬件,传输速度是有上限的。当网络传输速度过大,达到网卡上限时,就会发生丢包。这种情况一般常见于压测场景。
我们可以通过ethtool加网卡名,获得当前网卡支持的最大速度。
# ethtool eth0
Settings for eth0:
Speed: 10000Mb/s
可以看到,我这边用的网卡能支持的最大传输速度speed=1000Mb/s。
也就是俗称的千兆网卡,但注意这里的单位是Mb,这里的b 是指 bit,而不是 Byte。1Byte=8bit。所以 10000Mb/s 还要除以 8,也就是理论上网卡最大传输速度是1000/8 = 125MB/s。
我们可以通过sar命令从网络接口层面来分析数据包的收发情况。
# sar -n DEV 1
Linux 3.10.0-1127.19.1.el7.x86_64 2022年07月27日 _x86_64_ (1 CPU)
08时35分39秒 IFACE rxpck/s txpck/s rxkB/s txkB/s rxcmp/s txcmp/s rxmcst/s
08时35分40秒 eth0 6.06 4.04 0.35 121682.33 0.00 0.00 0.00
其中 txkB/s 是指当前每秒发送的字节(byte)总数,rxkB/s 是指每秒接收的字节(byte)总数。
当两者加起来的值约等于12~13w字节的时候,也就对应大概125MB/s的传输速度。此时达到网卡性能极限,就会开始丢包。
遇到这个问题,优先看下你的服务是不是真有这么大的真实流量,如果是的话可以考虑下拆分服务,或者就忍痛充钱升级下配置吧。
接收缓冲区丢包
我们一般使用TCP socket进行网络编程的时候,内核都会分配一个发送缓冲区和一个接收缓冲区。
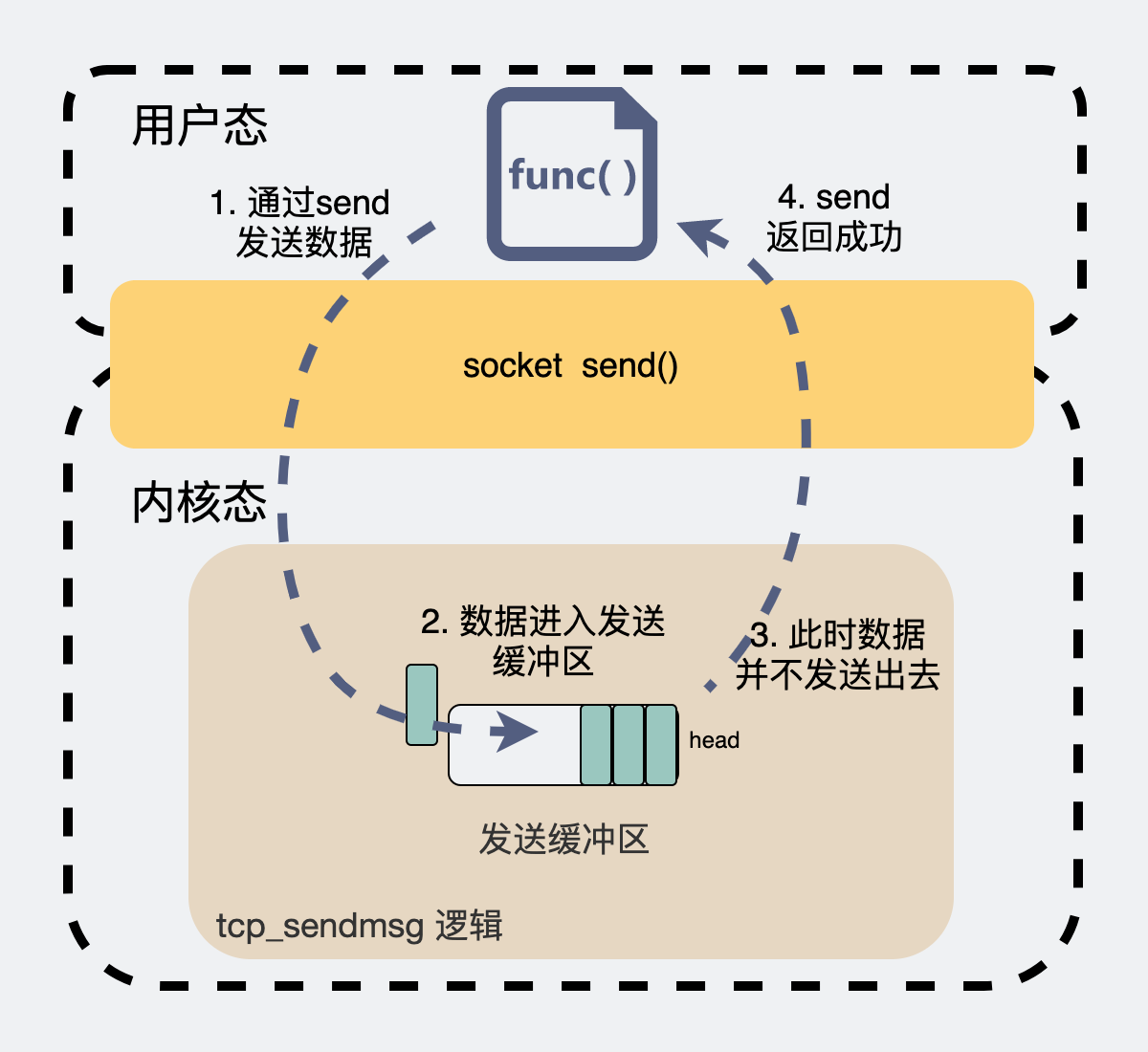
当我们想要发一个数据包,会在代码里执行send(msg),这时候数据包并不是一把梭直接就走网卡飞出去的。而是将数据拷贝到内核发送缓冲区就完事返回了,至于什么时候发数据,发多少数据,这个后续由内核自己做决定。之前写过的《代码执行 send 成功后,数据就发出去了吗?》里有比较详细的介绍。
而接收缓冲区作用也类似,从外部网络收到的数据包就暂存在这个地方,然后坐等用户空间的应用程序将数据包取走。
这两个缓冲区是有大小限制的,可以通过下面的命令去查看。
# 查看接收缓冲区
# sysctl net.ipv4.tcp_rmem
net.ipv4.tcp_rmem = 4096 87380 6291456
# 查看发送缓冲区
# sysctl net.ipv4.tcp_wmem
net.ipv4.tcp_wmem = 4096 16384 4194304
不管是接收缓冲区还是发送缓冲区,都能看到三个数值,分别对应缓冲区的最小值,默认值和最大值 (min、default、max)。缓冲区会在 min 和 max 之间动态调整。
那么问题来了,如果缓冲区设置过小会怎么样?
对于发送缓冲区,执行 send 的时候,如果是阻塞调用,那就会等,等到缓冲区有空位可以发数据。
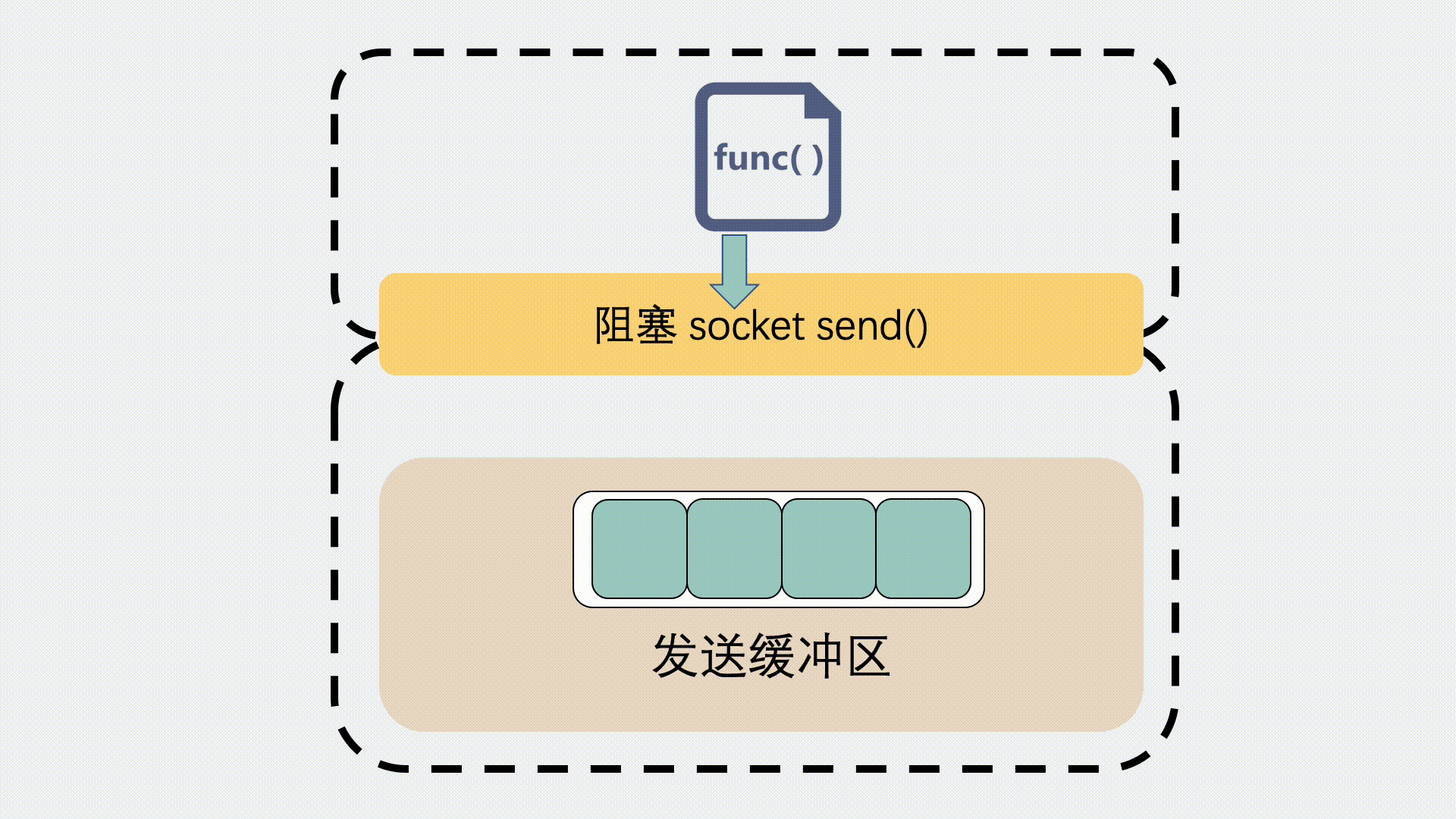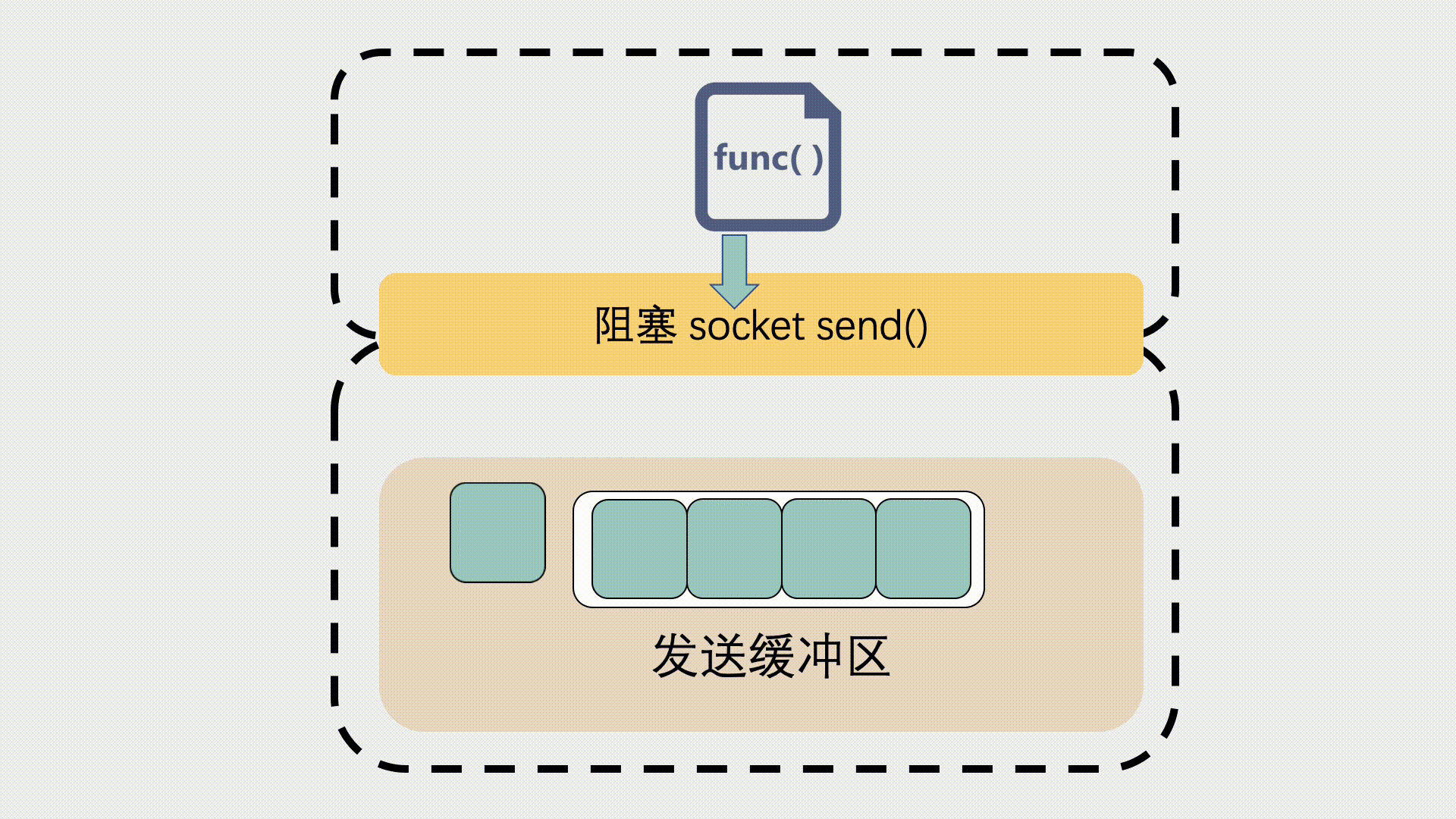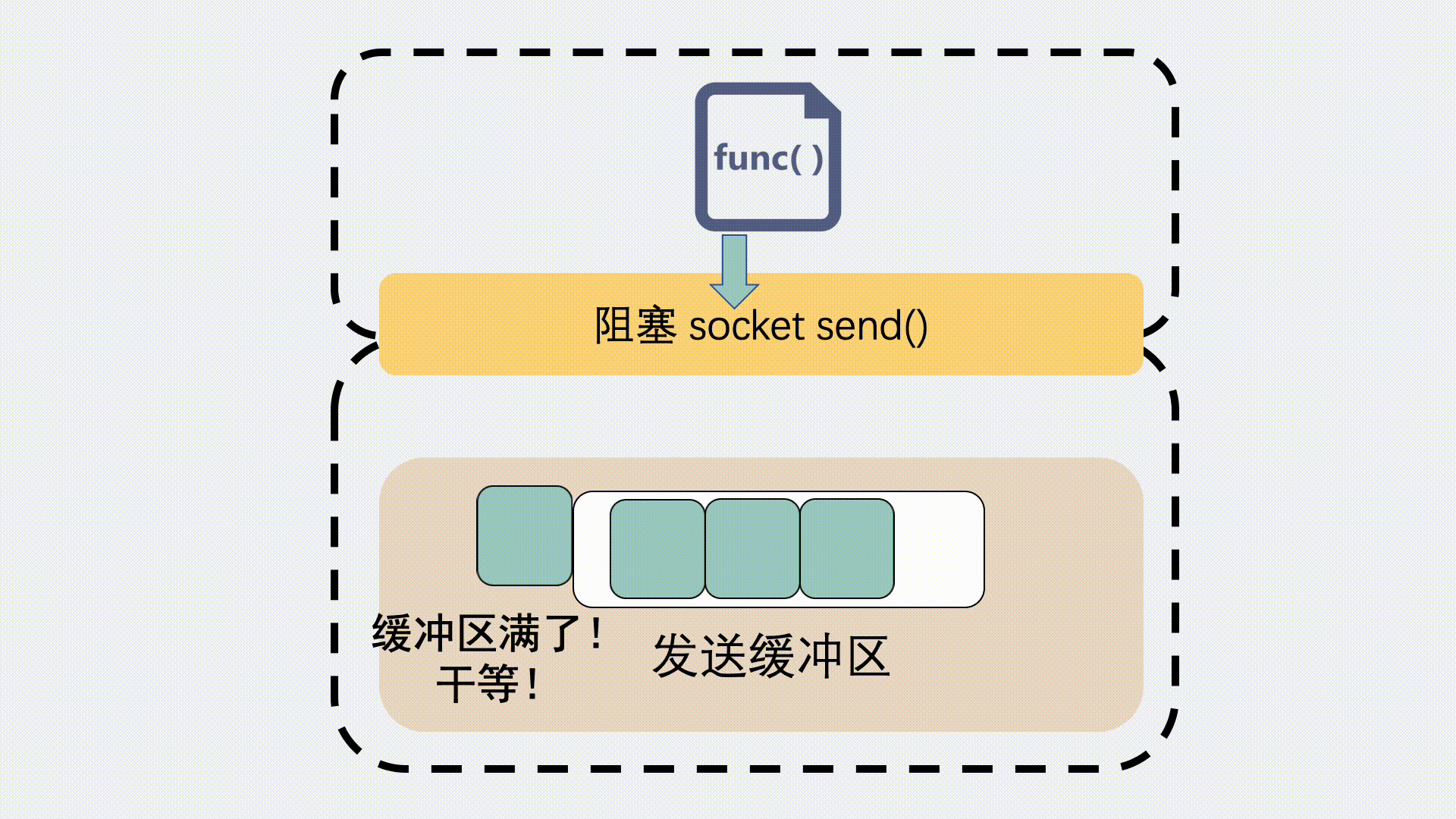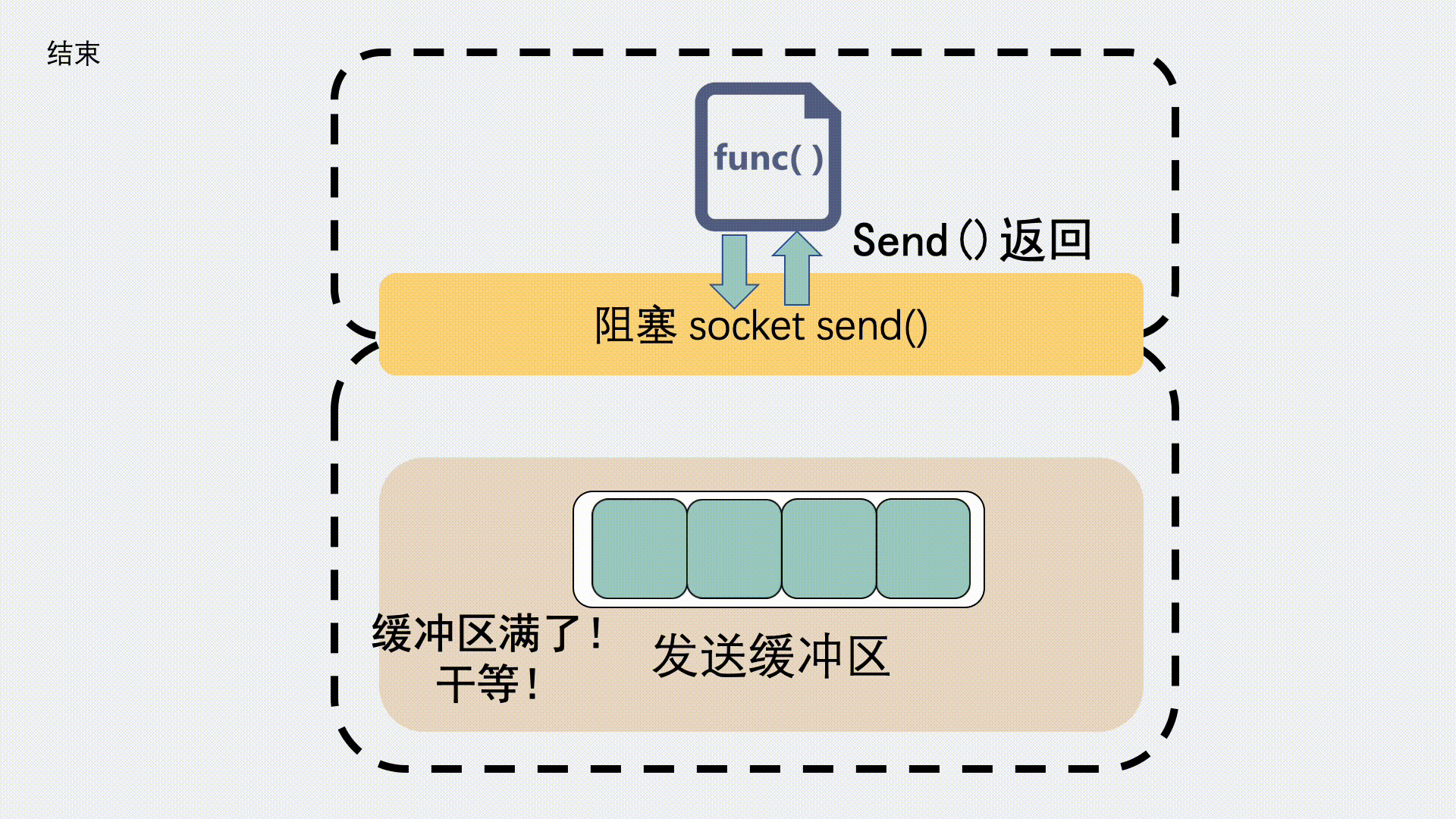
如果是非阻塞调用,就会立刻返回一个 EAGAIN 错误信息,意思是 Try again 。让应用程序下次再重试。这种情况下一般不会发生丢包。
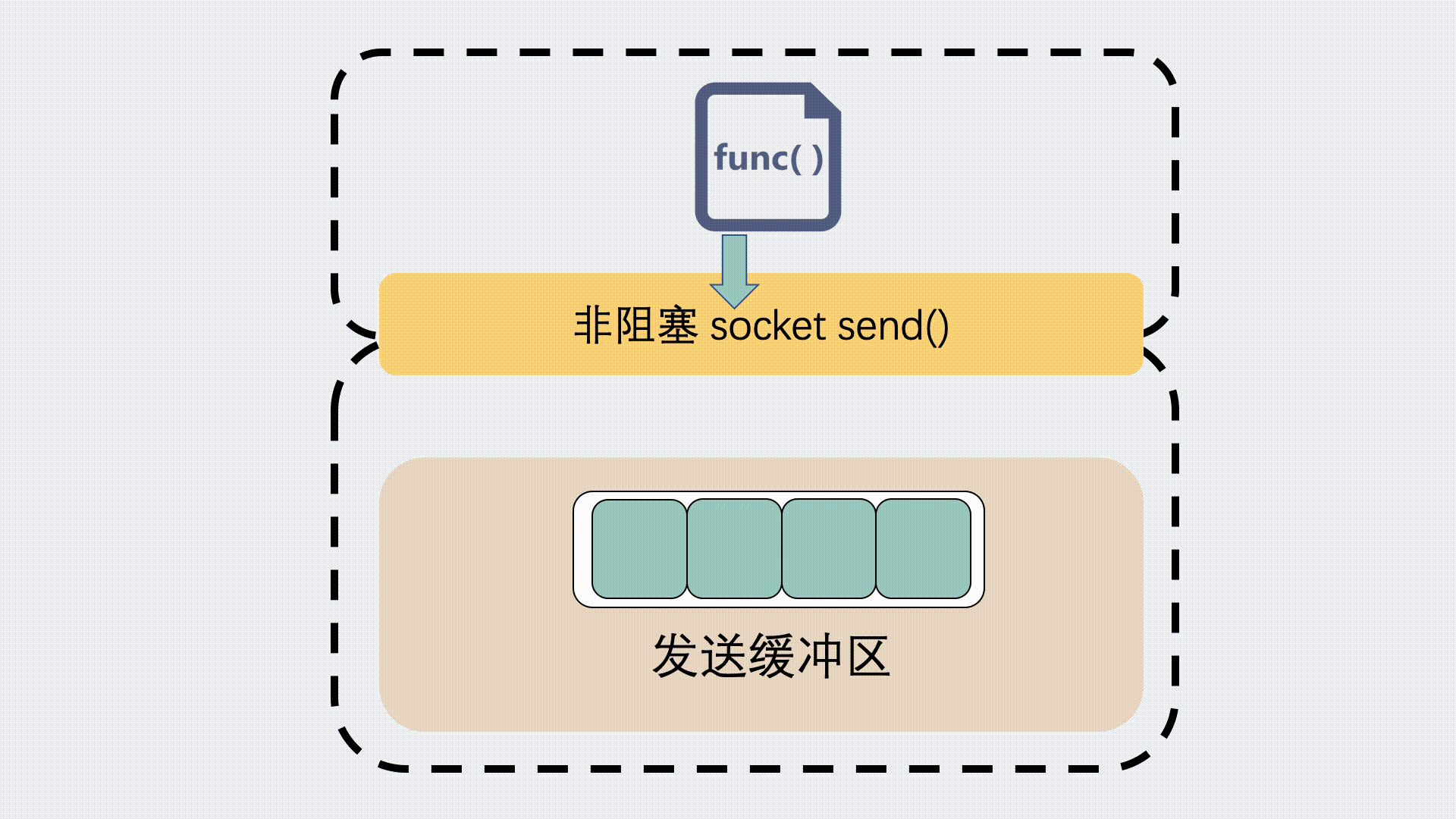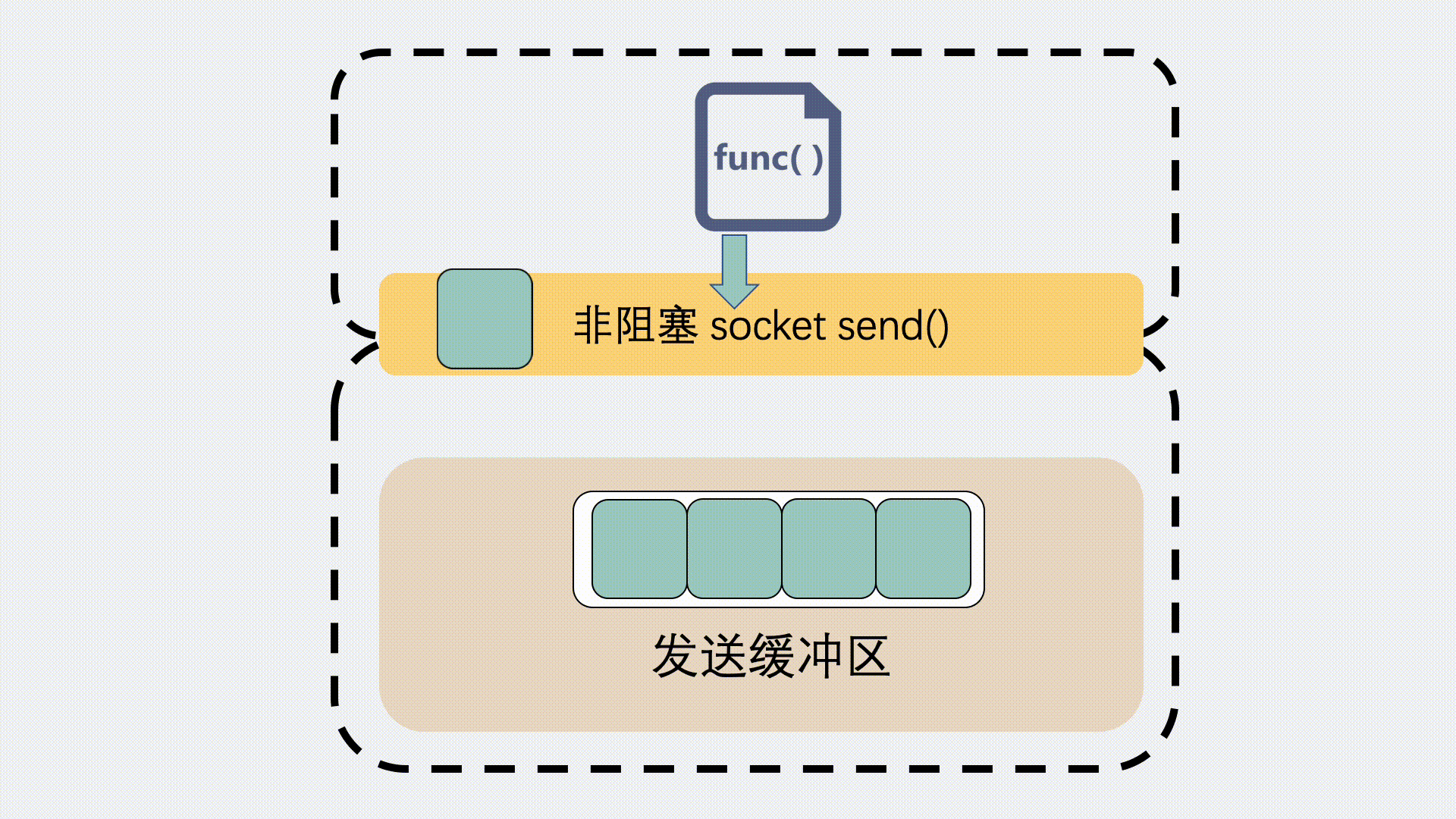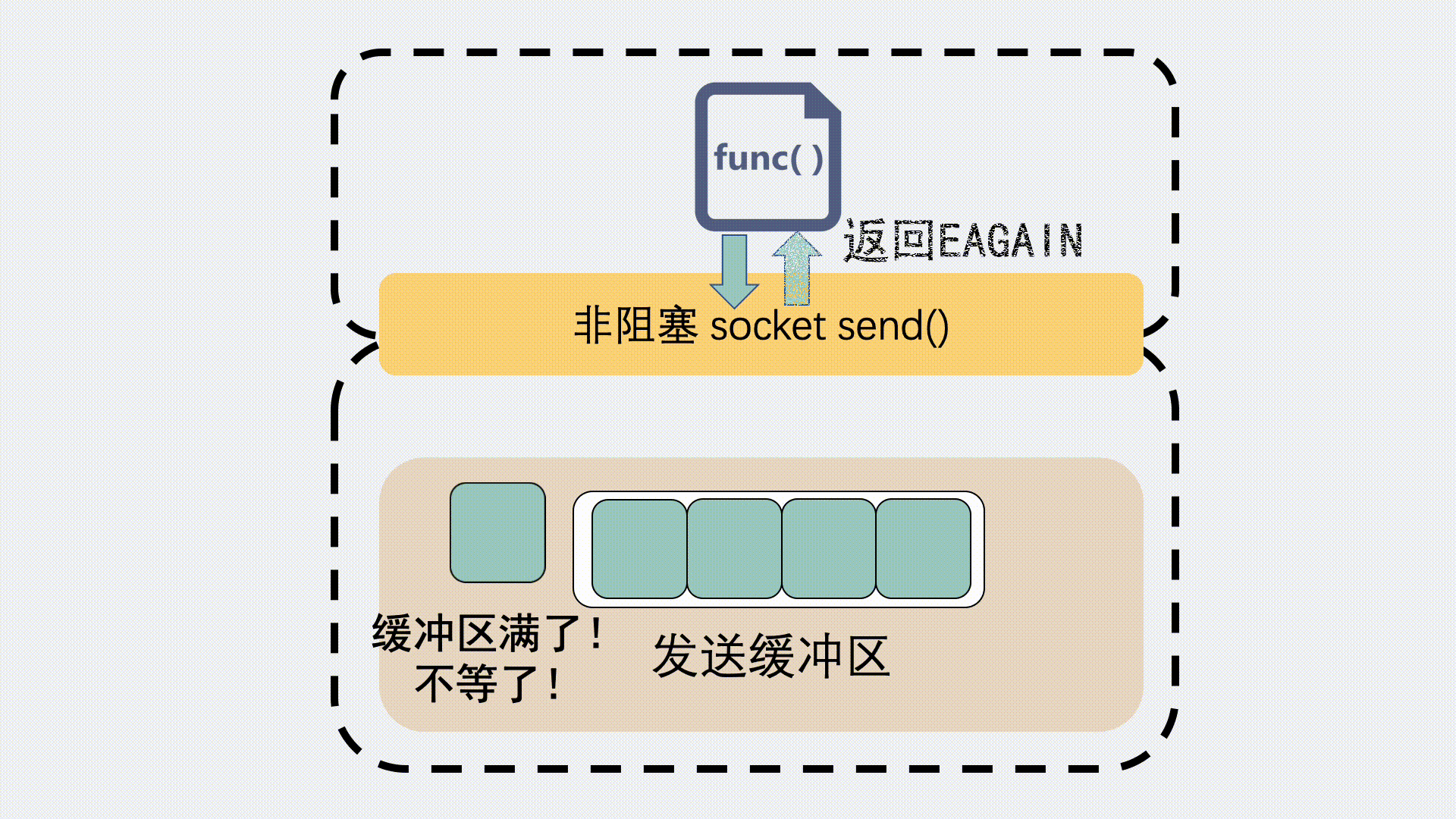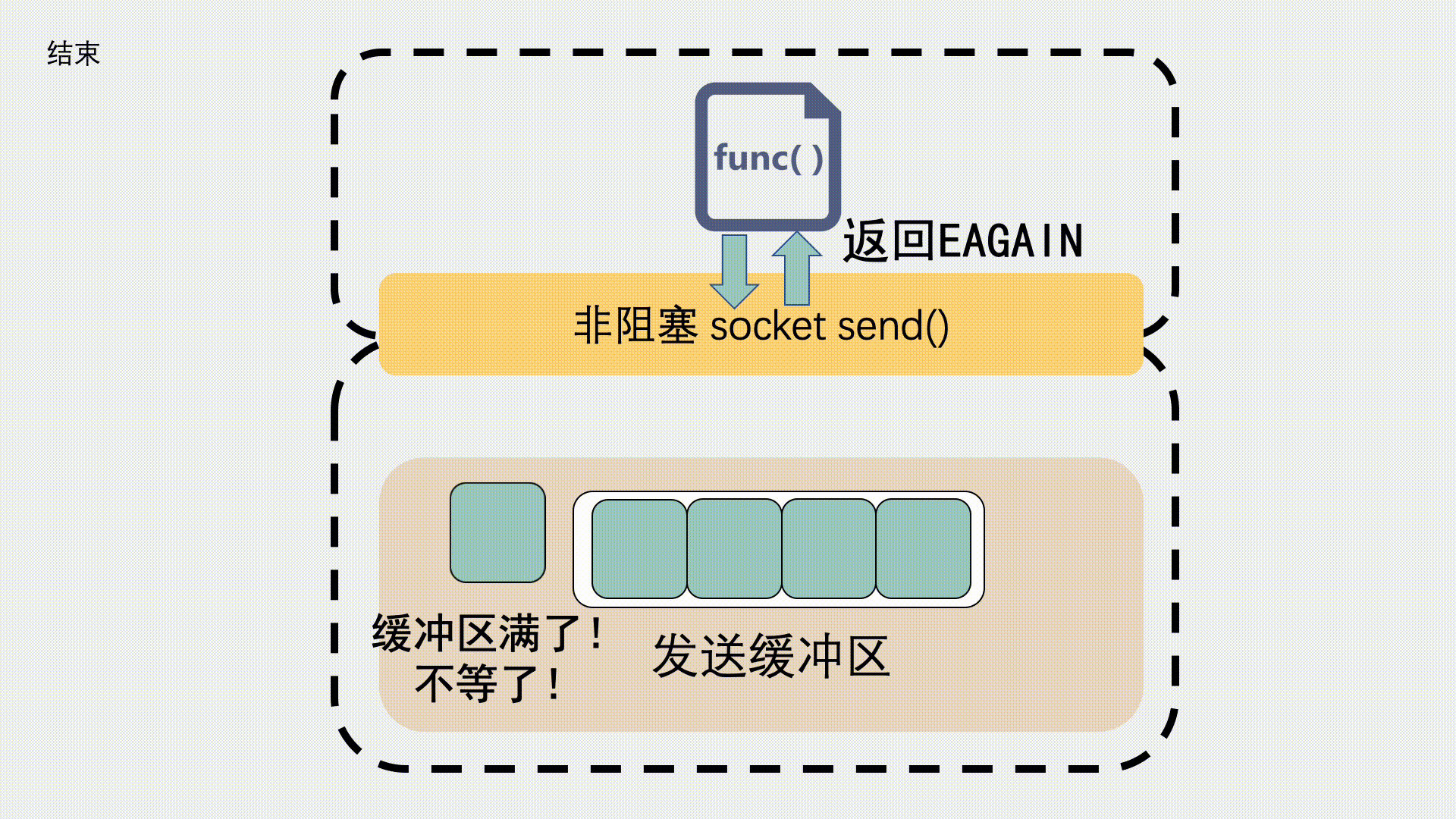
当接受缓冲区满了,事情就不一样了,它的 TCP 接收窗口会变为 0,也就是所谓的零窗口,并且会通过数据包里的win=0,告诉发送端,"球球了,顶不住了,别发了"。一般这种情况下,发送端就该停止发消息了,但如果这时候确实还有数据发来,就会发生丢包。
我们可以通过下面的命令里的TCPRcvQDrop查看到有没有发生过这种丢包现象。
cat /proc/net/netstat
TcpExt: SyncookiesSent TCPRcvQDrop SyncookiesFailed
TcpExt: 0 157 60116
但是说个伤心的事情,我们一般也看不到这个TCPRcvQDrop,因为这个是5.9版本里引入的打点,而我们的服务器用的一般是2.x~3.x左右版本。你可以通过下面的命令查看下你用的是什么版本的 linux 内核。
# cat /proc/version
Linux version 3.10.0-1127.19.1.el7.x86_64
两端之间的网络丢包
前面提到的是两端机器内部的网络丢包,除此之外,两端之间那么长的一条链路都属于外部网络,这中间有各种路由器和交换机还有光缆啥的,丢包也是很经常发生的。
这些丢包行为发生在中间链路的某些个机器上,我们当然是没权限去登录这些机器。但我们可以通过一些命令观察整个链路的连通情况。
ping 命令查看丢包
比如我们知道目的地的域名是 baidu.com。想知道你的机器到 baidu 服务器之间,有没有产生丢包行为。可以使用 ping 命令。
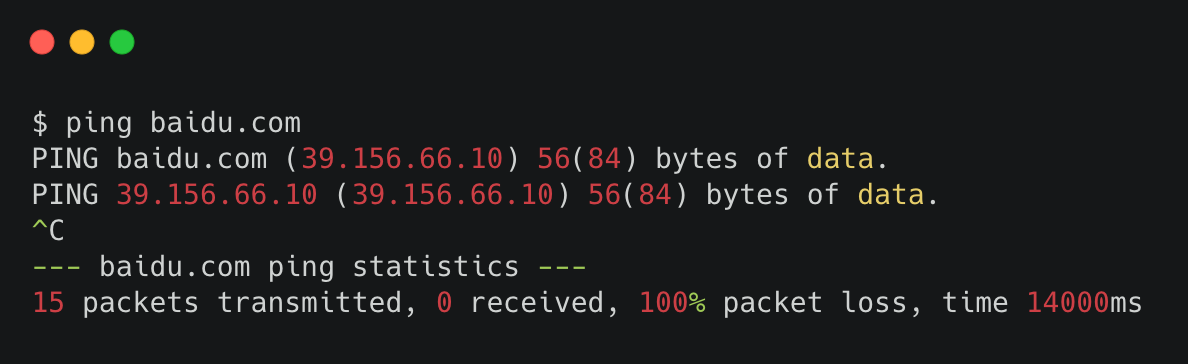
倒数第二行里有个100% packet loss,意思是丢包率 100%。
但这样其实你只能知道你的机器和目的机器之间有没有丢包。
那如果你想知道你和目的机器之间的这条链路,哪个节点丢包了,有没有办法呢?
有。
mtr 命令
mtr 命令可以查看到你的机器和目的机器之间的每个节点的丢包情况。
像下面这样执行命令。

其中**-r 是指 report**,以报告的形式打印结果。
可以看到Host那一列,出现的都是链路中间每一跳的机器,Loss的那一列就是指这一跳对应的丢包率。
需要注意的是,中间有一些是 host 是???,那个是因为mtr 默认用的是 ICMP 包,有些节点限制了ICMP 包,导致不能正常展示。
我们可以在 mtr 命令里加个-u,也就是使用udp 包,就能看到**部分???**对应的 IP。
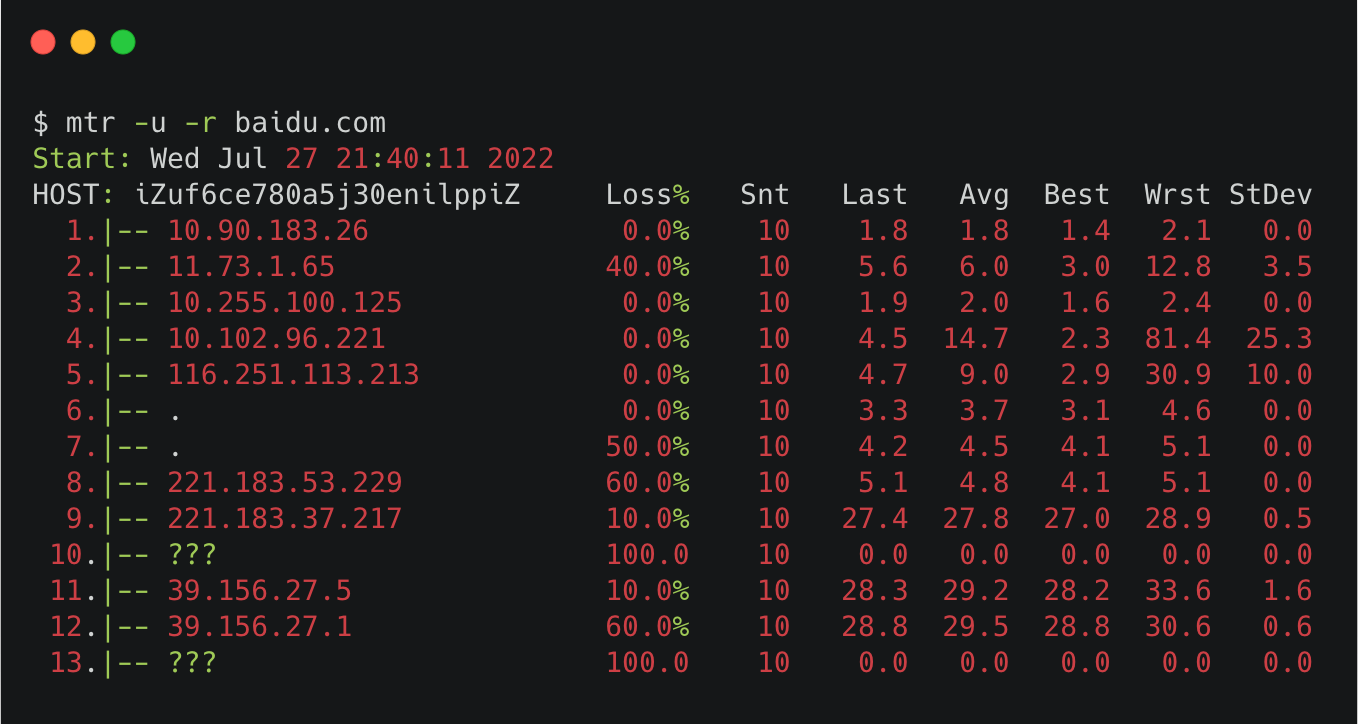
把ICMP 包和 UDP 包的结果拼在一起看,就是比较完整的链路图了。
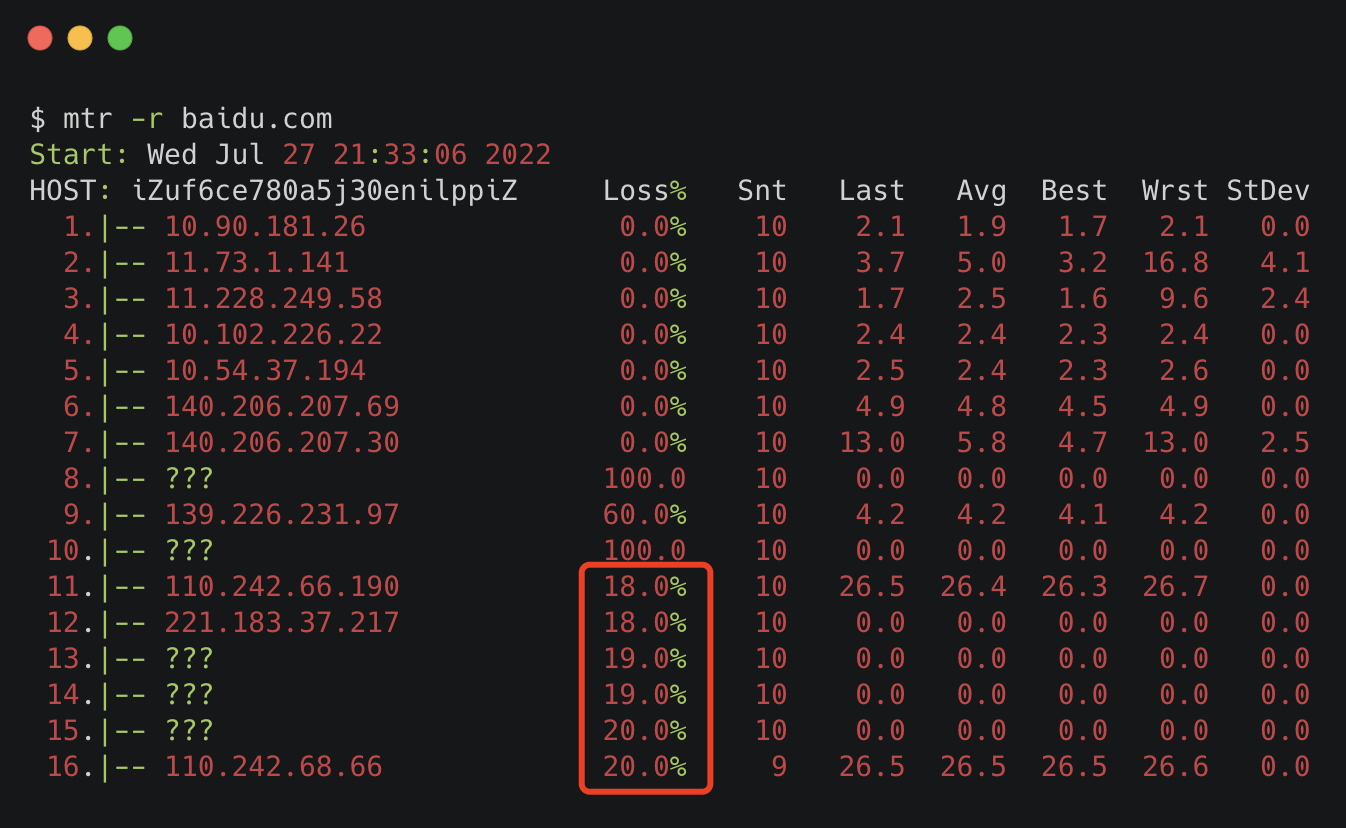
还有个小细节,Loss那一列,我们在 icmp 的场景下,关注最后一行,如果是 0%,那不管前面 loss 是 100%还是 80%都无所谓,那些都是节点限制导致的虚报。
但如果最后一行是 20%,再往前几行都是 20%左右,那说明丢包就是从最接近的那一行开始产生的,长时间是这样,那很可能这一跳出了点问题。如果是公司内网的话,你可以带着这条线索去找对应的网络同事。如果是外网的话,那耐心点等等吧,别人家的开发会比你更着急。
发生丢包了怎么办
说了这么多。只是想告诉大家,丢包是很常见的,几乎不可避免的一件事情。
但问题来了,发生丢包了怎么办?
这个好办,用TCP 协议去做传输。
建立了 TCP 连接的两端,发送端在发出数据后会等待接收端回复ack包,ack包的目的是为了告诉对方自己确实收到了数据,但如果中间链路发生了丢包,那发送端会迟迟收不到确认 ack,于是就会进行重传。以此来保证每个数据包都确确实实到达了接收端。
假设现在网断了,我们还用聊天软件发消息,聊天软件会使用 TCP 不断尝试重传数据,如果重传期间网络恢复了,那数据就能正常发过去。但如果多次重试直到超时都还是失败,这时候你将收获一个红色感叹号。
这时候问题又来了。
假设某绿皮聊天软件用的就是 TCP 协议。
那文章开头提到的女生,她男朋友回她的消息时为什么还会丢包?毕竟丢包了会重试,重试失败了还会出现红色感叹号。
于是乎,问题就变成了,用了 TCP 协议,就一定不会丢包吗?
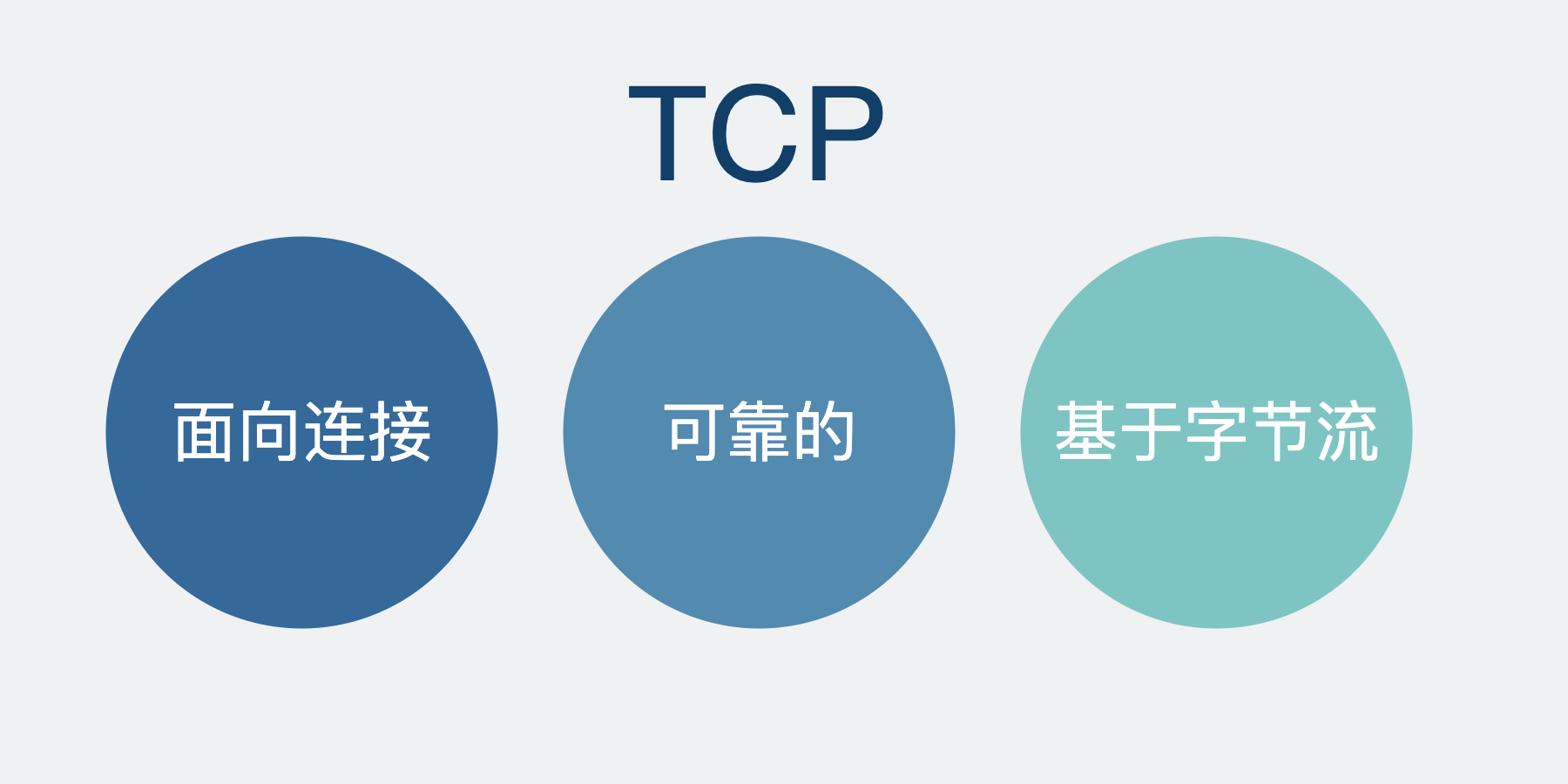
用了 TCP 协议就一定不会丢包吗
我们知道 TCP 位于传输层,在它的上面还有各种应用层协议,比如常见的 HTTP 或者各类 RPC 协议。
TCP 保证的可靠性,是传输层的可靠性。也就是说,TCP 只保证数据从 A 机器的传输层可靠地发到 B 机器的传输层。
至于数据到了接收端的传输层之后,能不能保证到应用层,TCP 并不管。
假设现在,我们输入一条消息,从聊天框发出,走到传输层 TCP 协议的发送缓冲区,不管中间有没有丢包,最后通过重传都保证发到了对方的传输层 TCP 接收缓冲区,此时接收端回复了一个ack,发送端收到这个ack后就会将自己发送缓冲区里的消息给扔掉。到这里 TCP 的任务就结束了。
TCP 任务是结束了,但聊天软件的任务没结束。
聊天软件还需要将数据从 TCP 的接收缓冲区里读出来,如果在读出来这一刻,手机由于内存不足或其他各种原因,导致软件崩溃闪退了。
发送端以为自己发的消息已经发给对方了,但接收端却并没有收到这条消息。
于是乎,消息就丢了。
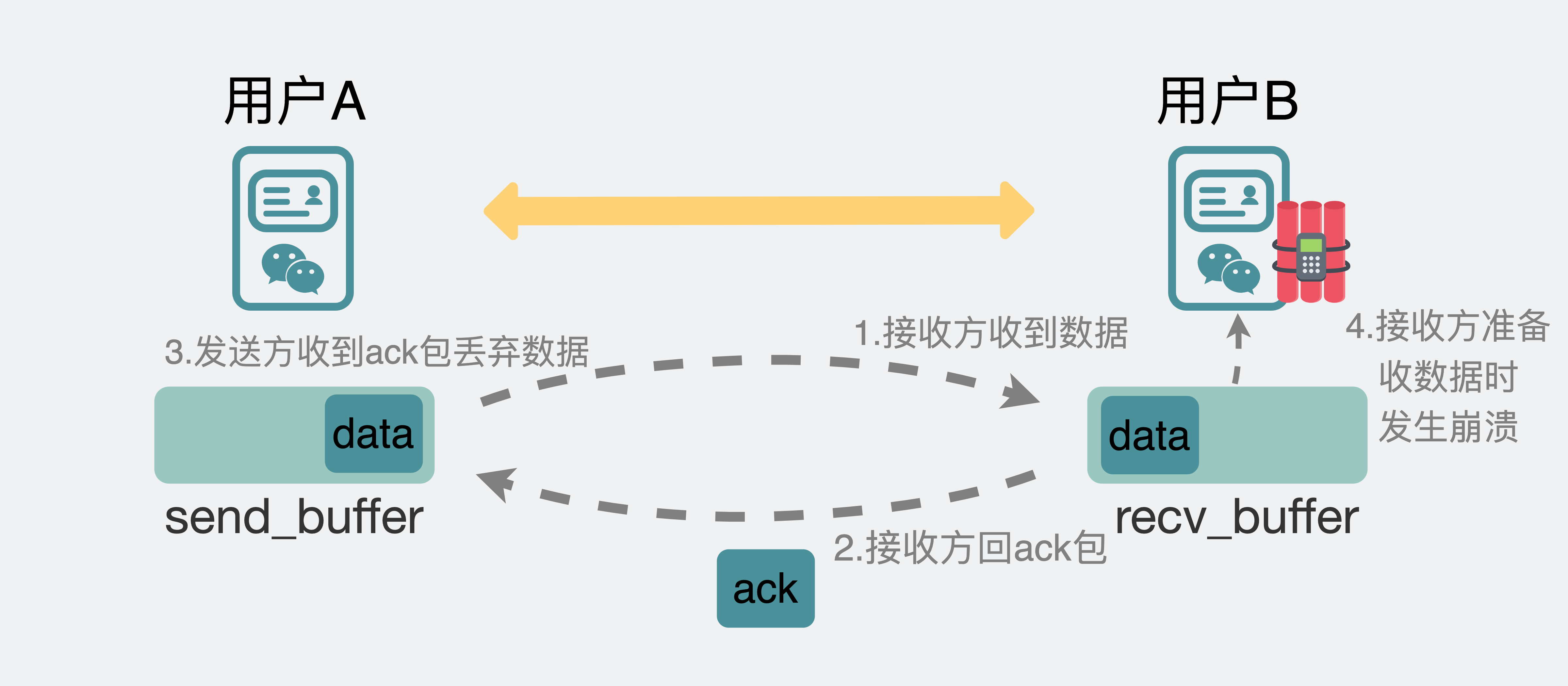
虽然概率很小,但它就是发生了。
合情合理,逻辑自洽。
所以从这里,我铿锵有力的得出结论,我的读者已经回了这位女生消息了,只是因为发生了丢包所以女生才没能收到,而丢包的原因是女生的手机聊天软件在接收消息的那一刻发生了闪退。
到这里。女生知道自己错怪她男朋友了,哭着表示,一定要让她男朋友给她买一台不闪退的最新款 iphone。
额。。。
兄弟们觉得我做得对的,请在评论区扣个"正能量"。
这类丢包问题怎么解决?
故事到这里也到尾声了,感动之余,我们来聊点掏心窝子的话。
其实前面说的都对,没有一句是假话。
但某绿皮聊天软件这么成熟,怎么可能没考虑过这一点呢。
大家应该还记得我们文章开头提到过,为了简单,就将服务器那一方给省略了,从三端通信变成了两端通信,所以才有了这个丢包问题。
现在我们重新将服务器加回来。
大家有没有发现,有时候我们在手机里聊了一大堆内容,然后登录电脑版,它能将最近的聊天记录都同步到电脑版上。也就是说服务器可能记录了我们最近发过什么数据,假设每条消息都有个 id,服务器和聊天软件每次都拿最新消息的 id进行对比,就能知道两端消息是否一致,就像对账一样。
对于发送方,只要定时跟服务端的内容对账一下,就知道哪条消息没发送成功,直接重发就好了。
如果接收方的聊天软件崩溃了,重启后跟服务器稍微通信一下就知道少了哪条数据,同步上来就是了,所以也不存在上面提到的丢包情况。
可以看出,TCP 只保证传输层的消息可靠性,并不保证应用层的消息可靠性。如果我们还想保证应用层的消息可靠性,就需要应用层自己去实现逻辑做保证。
那么问题叒来了,两端通信的时候也能对账,为什么还要引入第三端服务器?
主要有三个原因。
第一,如果是两端通信,你聊天软件里有
1000个好友,你就得建立1000个连接。但如果引入服务端,你只需要跟服务器建立1个连接就够了,聊天软件消耗的资源越少,手机就越省电。第二,就是安全问题,如果还是两端通信,随便一个人找你对账一下,你就把聊天记录给同步过去了,这并不合适吧。如果对方别有用心,信息就泄露了。引入第三方服务端就可以很方便的做各种鉴权校验。
第三,是软件版本问题。软件装到用户手机之后,软件更不更新就是由用户说了算了。如果还是两端通信,且两端的软件版本跨度太大,很容易产生各种兼容性问题,但引入第三端服务器,就可以强制部分过低版本升级,否则不能使用软件。但对于大部分兼容性问题,给服务端加兼容逻辑就好了,不需要强制用户更新软件。
所以看到这里大家应该明白了,我把服务端去掉,并不单纯是为了简单。
总结
数据从发送端到接收端,链路很长,任何一个地方都可能发生丢包,几乎可以说丢包不可避免。
平时没事也不用关注丢包,大部分时候 TCP 的重传机制保证了消息可靠性。
当你发现服务异常的时候,比如接口延时很高,总是失败的时候,可以用 ping 或者 mtr 命令看下是不是中间链路发生了丢包。
TCP 只保证传输层的消息可靠性,并不保证应用层的消息可靠性。如果我们还想保证应用层的消息可靠性,就需要应用层自己去实现逻辑做保证。
最后给大家留个问题吧,mtr 命令是怎么知道每一跳的 IP 地址的?
参考资料
《Linux 内核技术实战》-- 极客时间
《云网络丢包故障定位全景指南》--极客重生
最后
我一想到读者里还有不少兄弟还是单身,我就夜不能寐。
手心手背都是肉,一碗水要端平。
犹豫了很久,为她指了条明路。
"我读者里有很多微信不丢包的兄弟,他们都喜欢在我的文章底下点赞和再看。你可以考虑下他们"
"还有经常在我评论区叫我靓仔的那些个兄弟,一看就是深情种,请重点考虑"。
只能帮到这里了,懂?
我知道,这时候肯定就有兄弟要说我了,"故事汇都不敢这么编!"

嗯。
他们不敢,我敢。
别说了,一起在知识的海洋里呛水吧
关注公众号:【小白 debug】
不满足于在留言区说骚话?
加我,我们建了个划水吹牛皮群,在群里,你可以跟你下次跳槽可能遇到的同事或面试官聊点有意思的话题。就超!开!心!