TCP粘包 数据包:我只是犯了每个数据包都会犯的错 |硬核图解

事情从一个健身教练说起吧。

李东,自称亚健康终结者,尝试使用互联网+的模式拓展自己的业务。在某款新开发的聊天软件琛琛上发布广告。
键盘说来就来。疯狂发送"李东",回车发送!,"亚健康终结者",再回车发送!

还记得四层网络协议长什么样子吗?
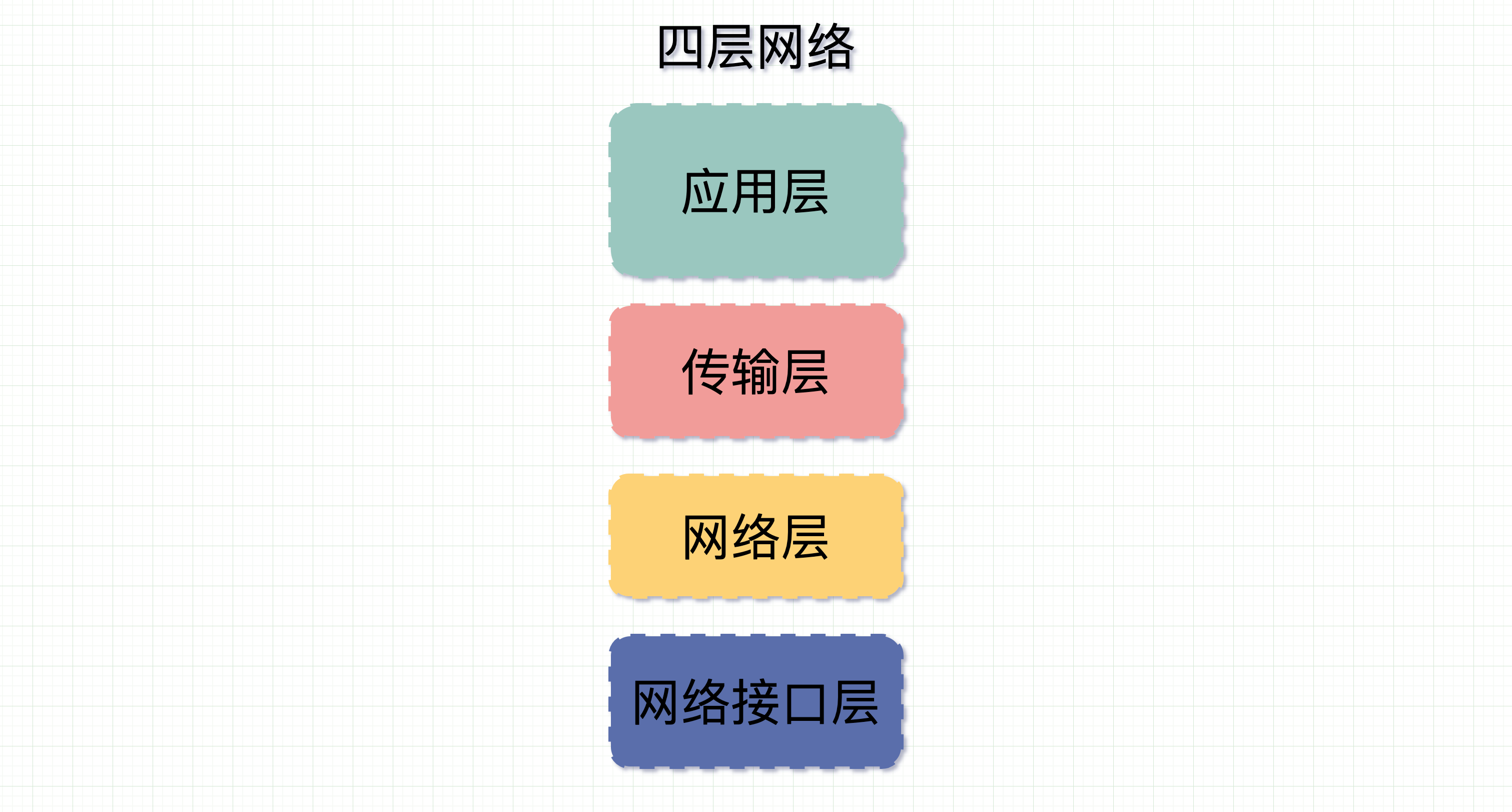
四层网络模型每层各司其职,消息在进入每一层时都会多加一个报头,每多一个报头可以理解为数据报多戴一顶帽子。这个报头上面记录着消息从哪来,到哪去,以及消息多长等信息。比如,mac头部记录的是硬件的唯一地址,IP头记录的是从哪来和到哪去,传输层头记录到是到达目的主机后具体去哪个进程。
在从消息发到网络的时候给消息带上报头,消息和纷繁复杂的网络中通过这些信息在路由器间流转,最后到达目的机器上,接受者再通过这些报头,一步一步还原出发送者最原始要发送的消息。

为什么要将数据切片
软件琛琛是属于应用层上的。
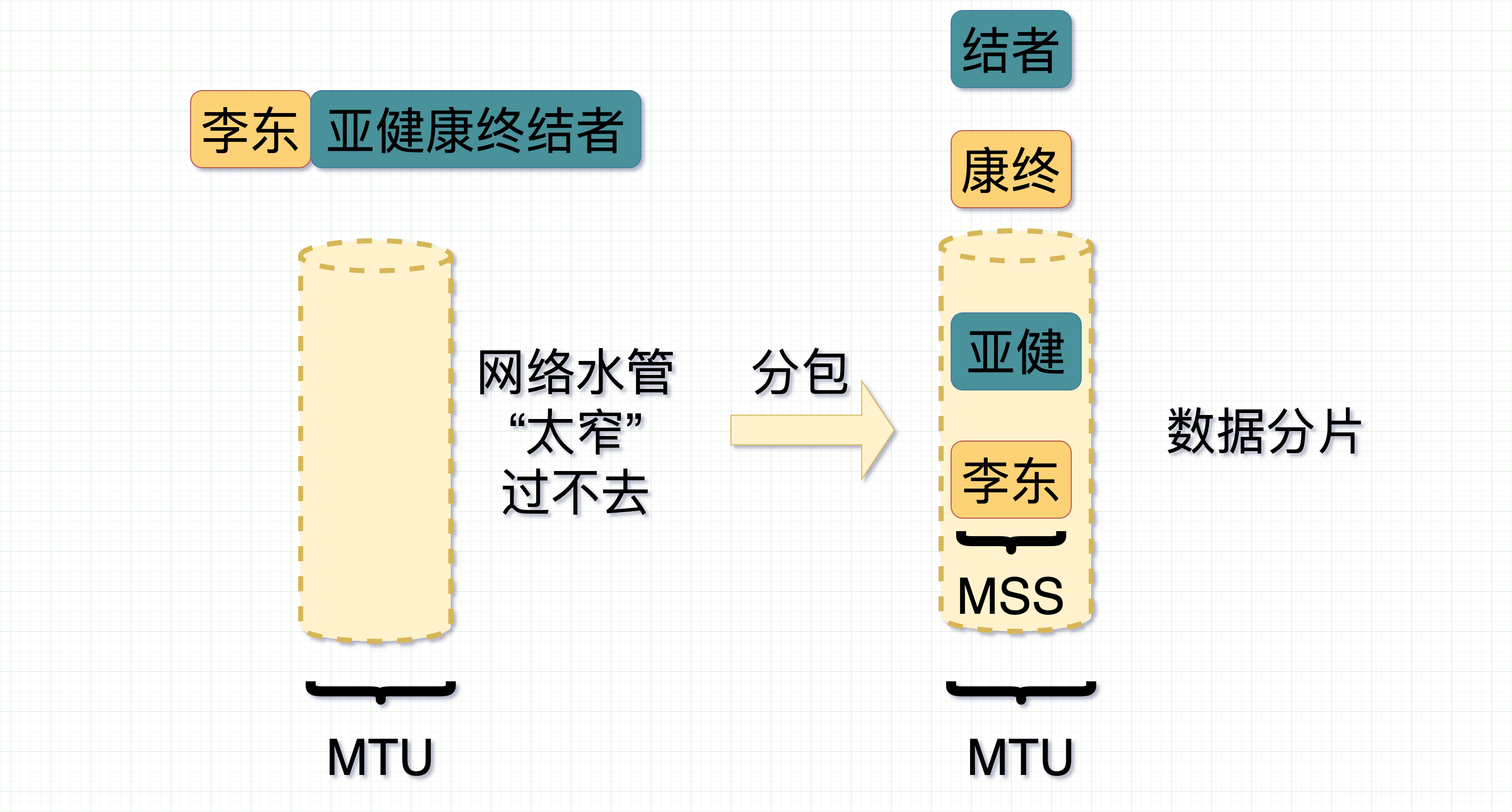
而"李东","亚健康终结者"这两条消息在进入传输层时使用的是传输层上的 TCP 协议。消息在进入**传输层(TCP)**时会被切片为一个个数据包。这个数据包的长度是MSS。
可以把网络比喻为一个水管,是有一定的粗细的,这个粗细由网络接口层(数据链路层)提供给网络层,一般认为是的MTU(1500),直接传入整个消息,会超过水管的最大承受范围,那么,就需要进行切片,成为一个个数据包,这样消息才能正常通过“水管”。
MTU 和 MSS 有什么区别
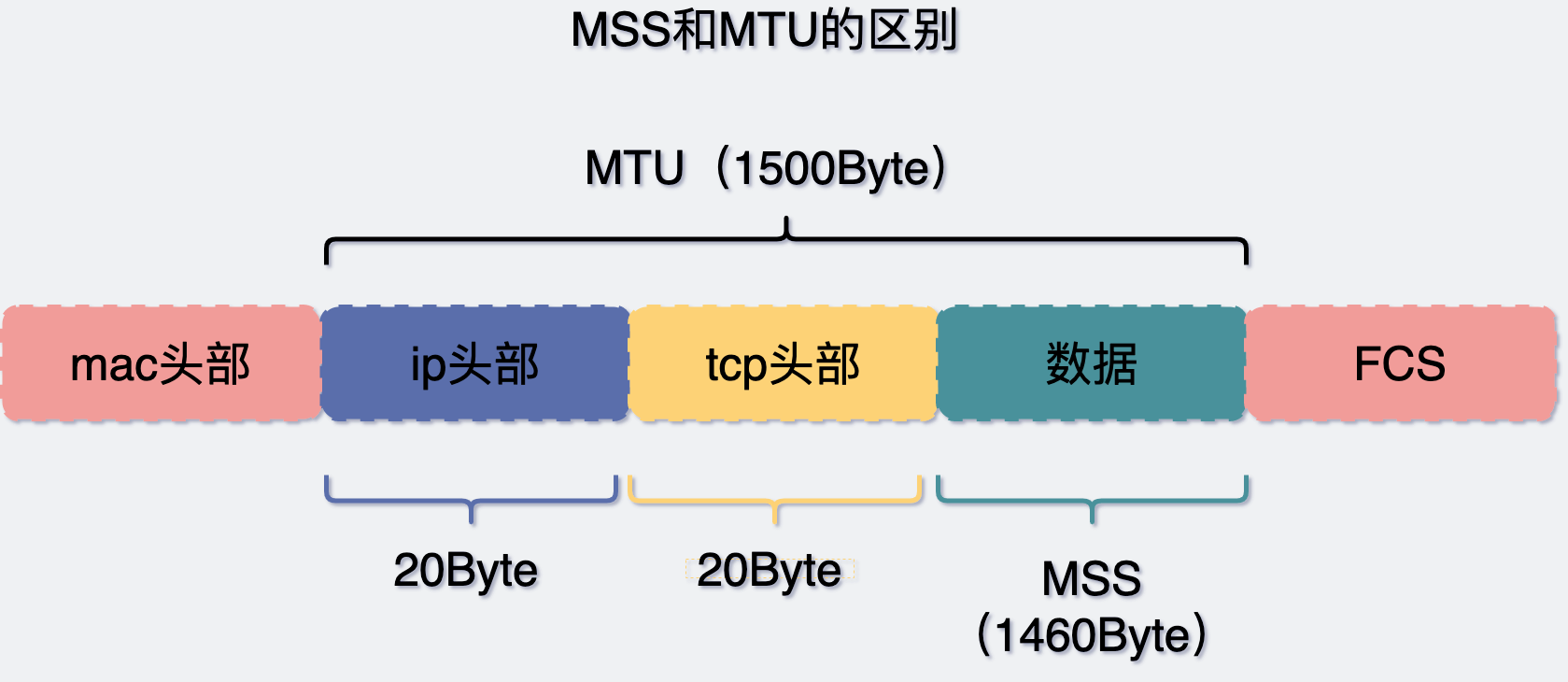
MTU: Maximum Transmit Unit,最大传输单元。 由网络接口层(数据链路层)提供给网络层最大一次传输数据的大小;一般 MTU=1500 Byte。
假设 IP 层有 <= 1500 byte 需要发送,只需要一个 IP 包就可以完成发送任务;假设 IP 层有> 1500 byte 数据需要发送,需要分片才能完成发送,分片后的 IP Header ID 相同。MSS:Maximum Segment Size 。 TCP 提交给 IP 层最大分段大小,不包含 TCP Header 和 TCP Option,只包含 TCP Payload ,MSS 是 TCP 用来限制应用层最大的发送字节数。
假设 MTU= 1500 byte,那么 MSS = 1500- 20(IP Header) -20 (TCP Header) = 1460 byte,如果应用层有 2000 byte 发送,那么需要两个切片才可以完成发送,第一个 TCP 切片 = 1460,第二个 TCP 切片 = 540。
什么是粘包
那么当李东在手机上键入"李东""亚健康终结者"的时候,在 TCP 中把消息分成 MSS 大小后,消息顺着网线顺利发出。
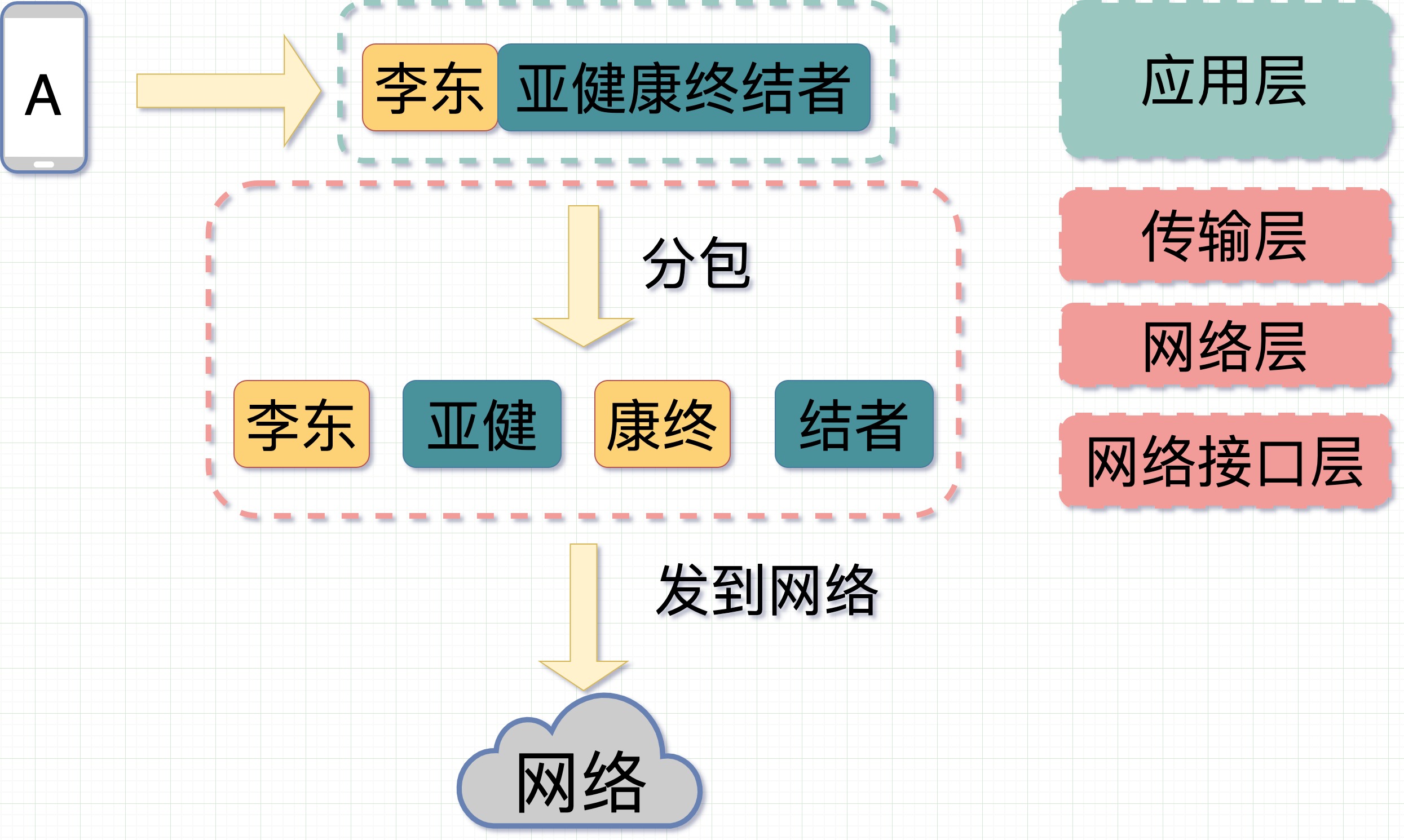
网络稳得很,将消息分片传到了对端手机 B 上。经过 TCP 层消息重组。变成"李东亚健康终结者"这样的字节流(stream)。
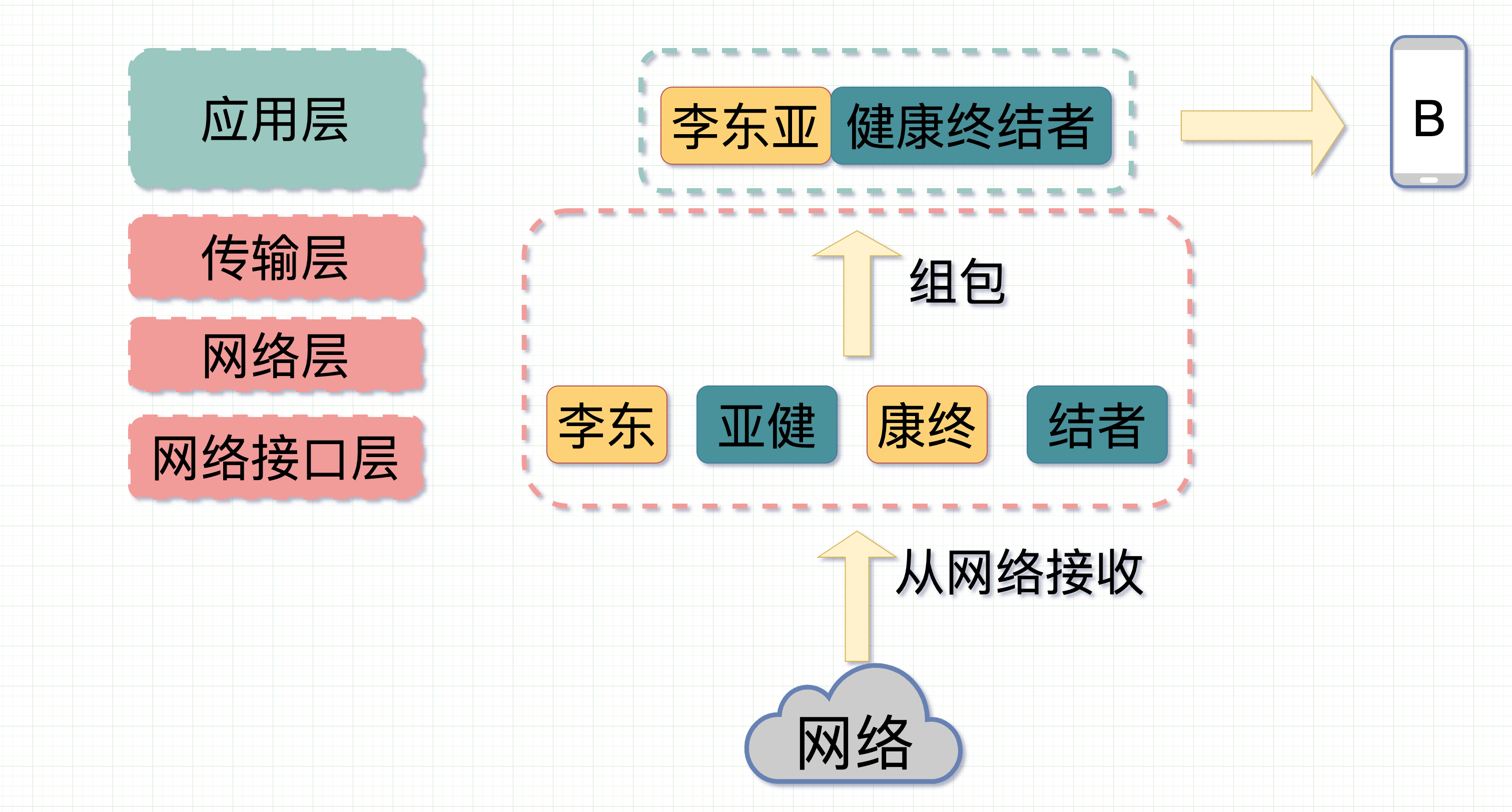
但由于聊天软件琛琛是新开发的,而且开发者叫小白,完了,是个臭名昭著的造 bug 工程师。经过他的代码,在处理字节流的时候消息从"李东","亚健康终结者"变成了"李东亚","健康终结者"。"李东"作为上一个包的内容与下一个包里的"亚"粘在了一起被错误地当成了一个数据包解析了出来。这就是所谓的粘包。
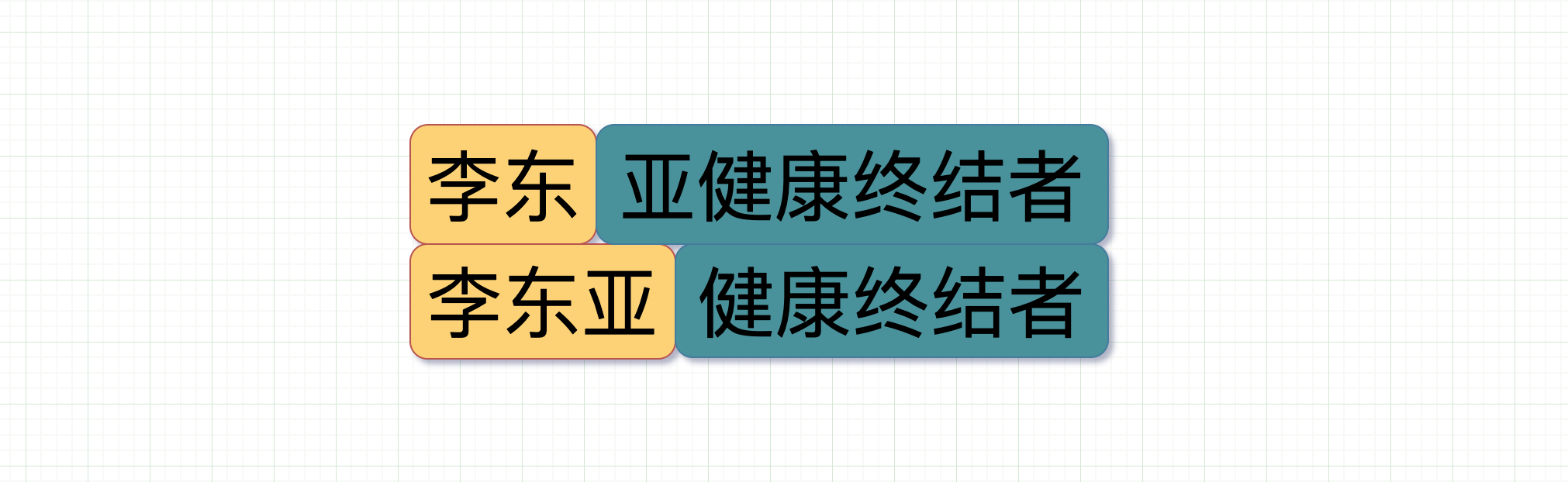
一个号称健康终结者的健身教练,大概运气也不会很差吧,就祝他客源滚滚吧。
为什么会出现粘包
那就要从 TCP 是啥说起。
TCP,Transmission Control Protocol。传输控制协议,是一种面向连接的、可靠的、基于字节流的传输层通信协议。

其中跟粘包关系最大的就是基于字节流这个特点。
字节流可以理解为一个双向的通道里流淌的数据,这个数据其实就是我们常说的二进制数据,简单来说就是一大堆 01 串。这些 01 串之间没有任何边界。
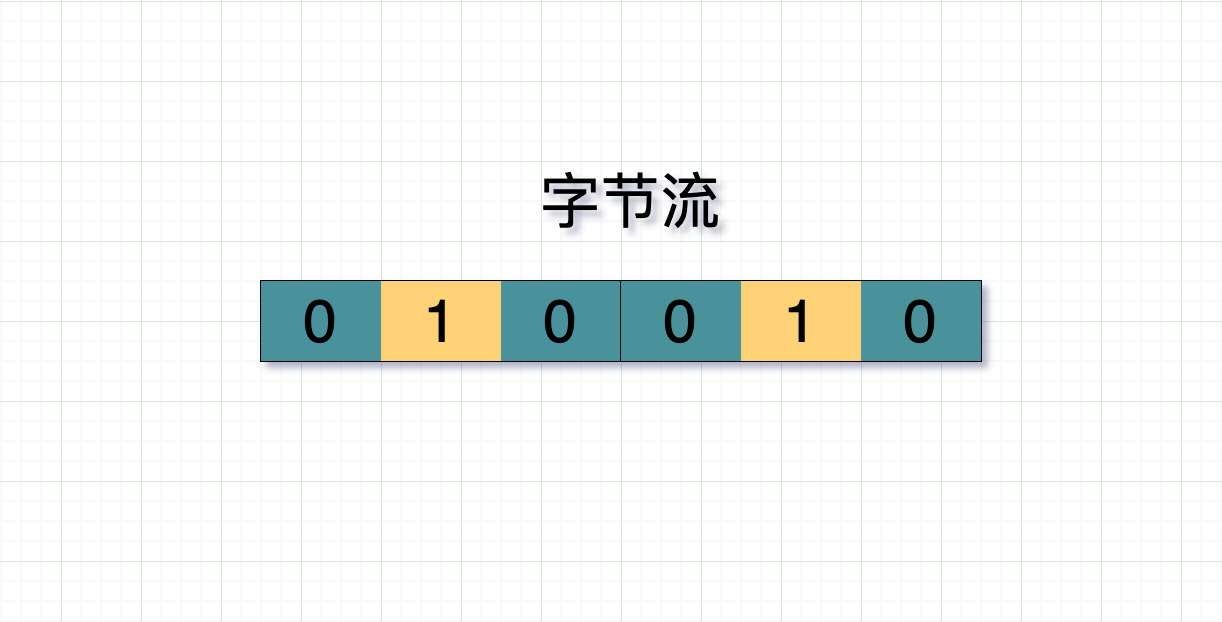
应用层传到 TCP 协议的数据,不是以消息报为单位向目的主机发送,而是以字节流的方式发送到下游,这些数据可能被切割和组装成各种数据包,接收端收到这些数据包后没有正确还原原来的消息,因此出现粘包现象。
为什么要组装发送的数据
上面提到 TCP 切割数据包是为了能顺利通过网络这根水管。相反,还有一个组装的情况。如果前后两次 TCP 发的数据都远小于 MSS,比如就几个字节,每次都单独发送这几个字节,就比较浪费网络 io 。
比如小白爸让小白出门给买一瓶酱油,小白出去买酱油回来了。小白妈又让小白出门买一瓶醋回来。小白前后结结实实跑了两趟,影响了打游戏的时间。
优化的方法也比较简单。当小白爸让小白去买酱油的时候,小白先等待,继续打会游戏,这时候如果小白妈让小白买瓶醋回来,小白可以一次性带着两个需求出门,再把东西带回来。
上面说的其实就是TCP的 Nagle 算法优化,目的是为了避免发送小的数据包。
在 Nagle 算法开启的状态下,数据包在以下两个情况会被发送:
- 如果包长度达到
MSS(或含有Fin包),立刻发送,否则等待下一个包到来;如果下一包到来后两个包的总长度超过MSS的话,就会进行拆分发送; - 等待超时(一般为
200ms),第一个包没到MSS长度,但是又迟迟等不到第二个包的到来,则立即发送。

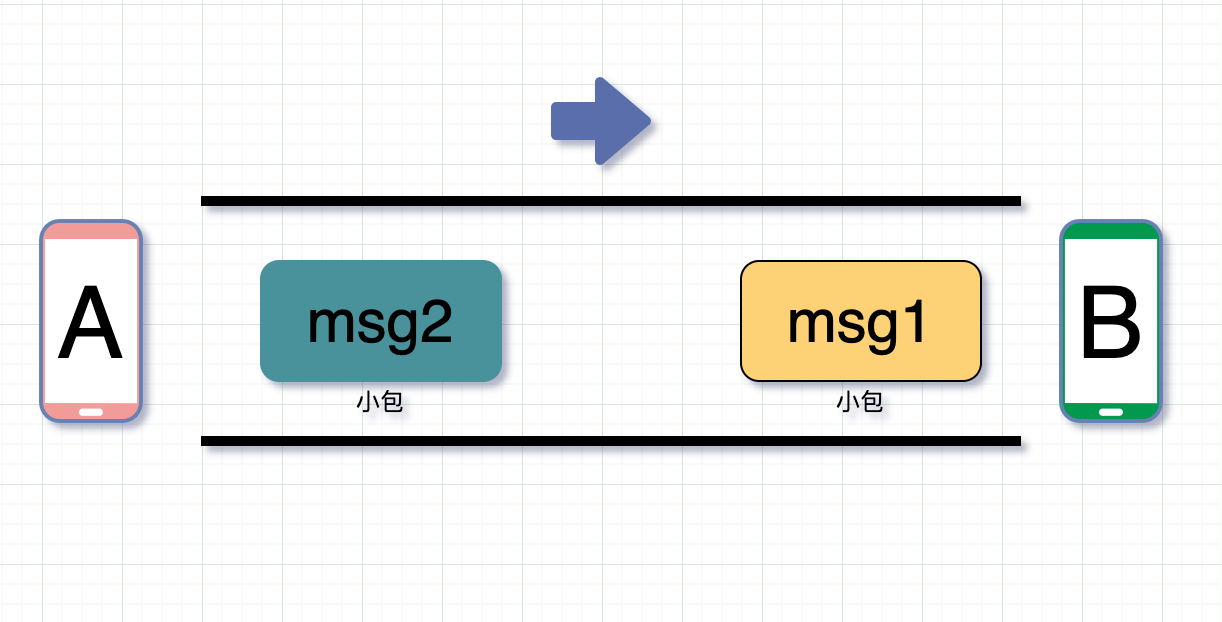
- 由于启动了Nagle 算法, msg1 小于 mss ,此时等待
200ms内来了一个 msg2 ,msg1 + msg2 > MSS,因此把 msg2 分为 msg2(1) 和 msg2(2),msg1 + msg2(1) 包的大小为MSS。此时发送出去。 - 剩余的 msg2(2) 也等到了 msg3, 同样 msg2(2) + msg3 > MSS,因此把 msg3 分为 msg3(1) 和 msg3(2),msg2(2) + msg3(1) 作为一个包发送。
- 剩余的 msg3(2) 长度不足
mss,同时在200ms内没有等到下一个包,等待超时,直接发送。 - 此时三个包虽然在图里颜色不同,但是实际场景中,他们都是一整个 01 串,如果处理开发者把第一个收到的 msg1 + msg2(1) 就当做是一个完整消息进行处理,就会看上去就像是两个包粘在一起,就会导致粘包问题。
关掉 Nagle 算法就不会粘包了吗?
Nagle 算法其实是个有些年代的东西了,诞生于 1984 年。对于应用程序一次发送一字节数据的场景,如果没有 Nagle 的优化,这样的包立马就发出去了,会导致网络由于太多的包而过载。
但是今天网络环境比以前好太多,Nagle 的优化帮助就没那么大了。而且它的延迟发送,有时候还可能导致调用延时变大,比如打游戏的时候,你操作如此丝滑,但却因为 Nagle 算法延迟发送导致慢了一拍,就问你难受不难受。
所以现在一般也会把它关掉。
看起来,Nagle 算法的优化作用貌似不大,还会导致粘包"问题"。那么是不是关掉这个算法就可以解决掉这个**粘包"问题"**呢?
TCP_NODELAY = 1
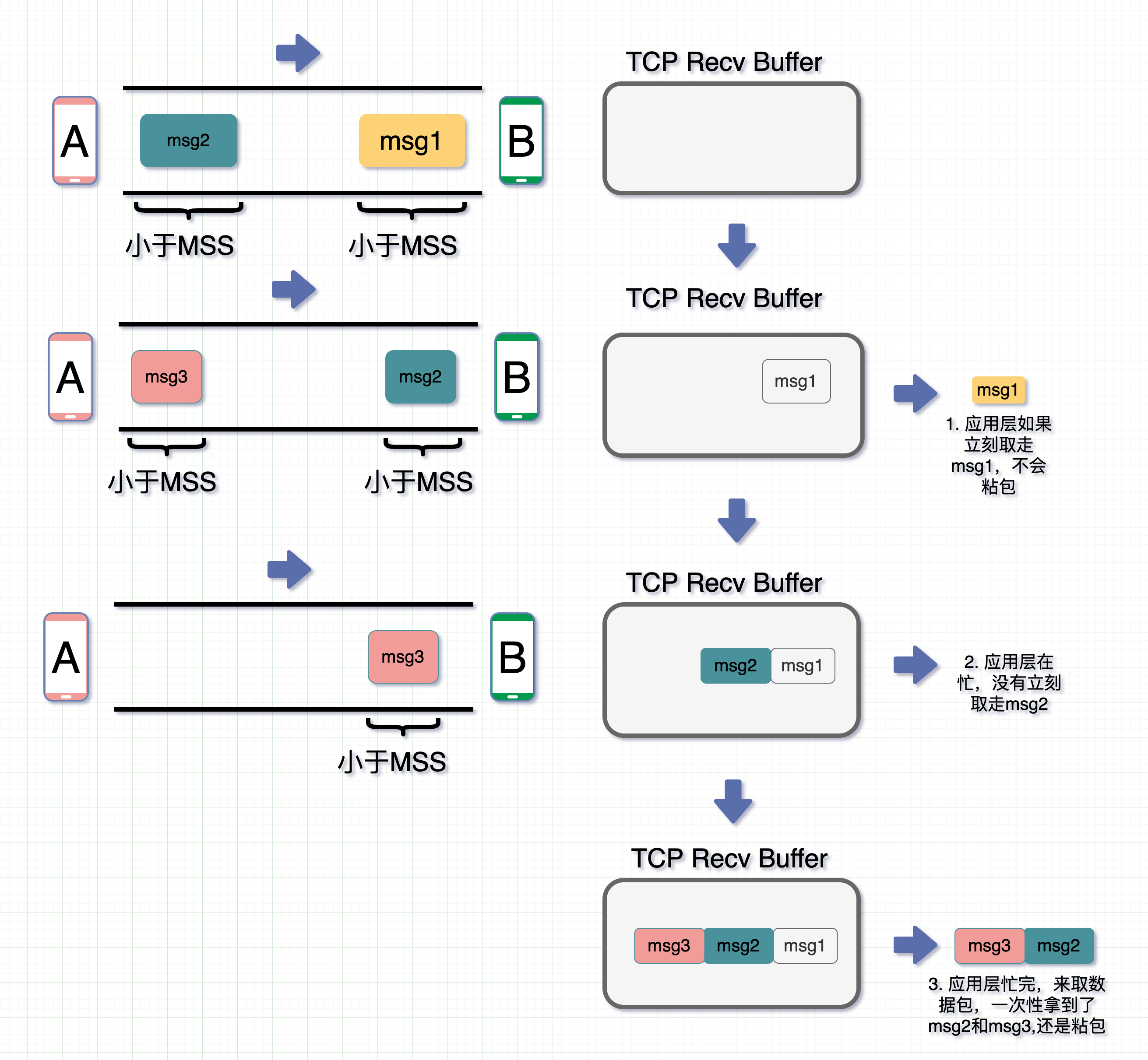
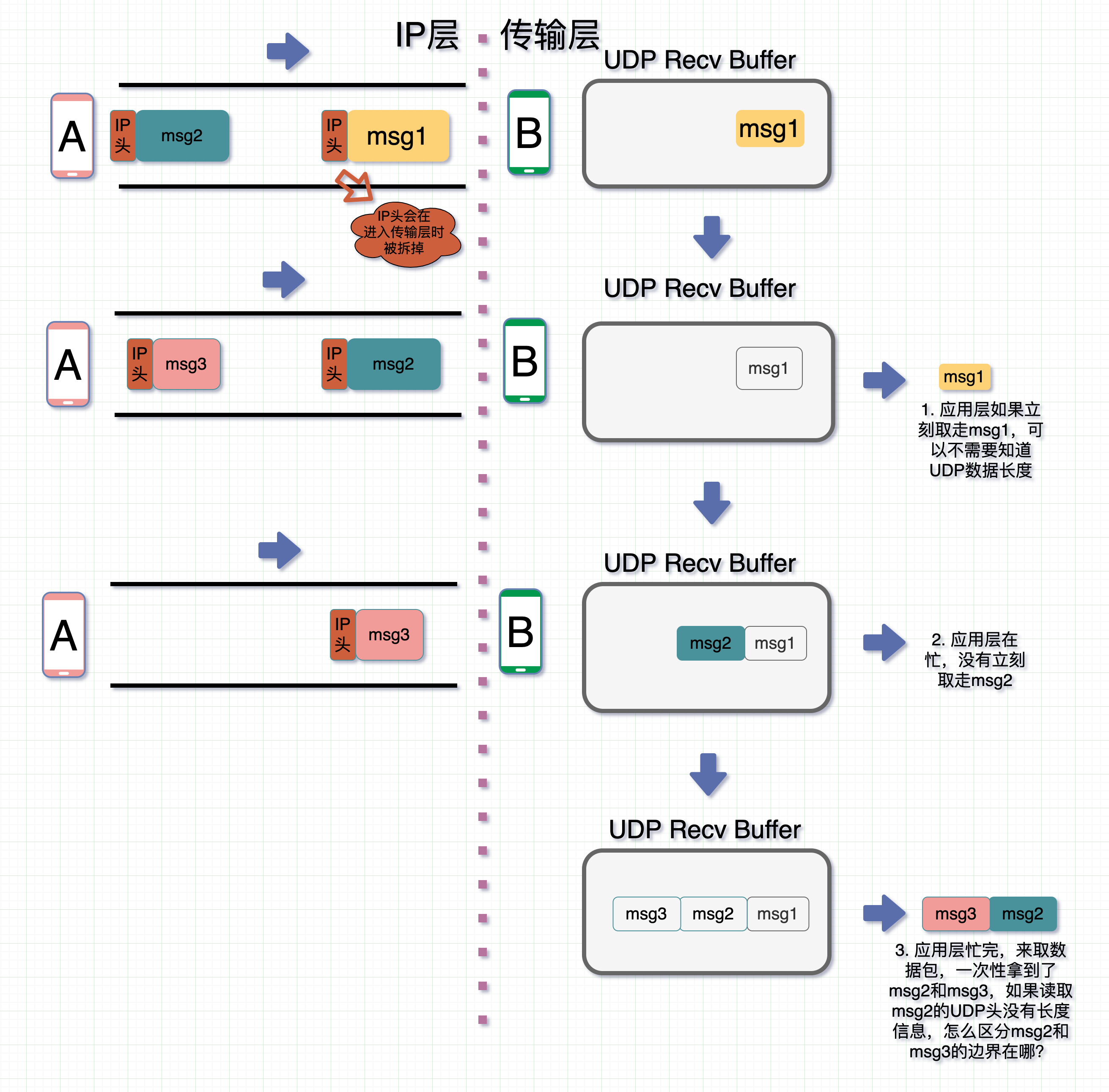
- 接受端应用层在收到 msg1 时立马就取走了,那此时 msg1 没粘包问题
- **msg2 **到了后,应用层在忙,没来得及取走,就呆在 TCP Recv Buffer 中了
- **msg3 **此时也到了,跟 msg2 和 msg3 一起放在了 TCP Recv Buffer 中
- 这时候应用层忙完了,来取数据,图里是两个颜色作区分,但实际场景中都是 01 串,此时一起取走,发现还是粘包。
因此,就算关闭 Nagle 算法,接收数据端的应用层没有及时读取 TCP Recv Buffer 中的数据,还是会发生粘包。

怎么处理粘包
粘包出现的根本原因是不确定消息的边界。接收端在面对**"无边无际"的二进制流的时候,根本不知道收了多少 01 才算一个消息**。一不小心拿多了就说是粘包。其实粘包根本不是 TCP 的问题,是使用者对于 TCP 的理解有误导致的一个问题。
只要在发送端每次发送消息的时候给消息带上识别消息边界的信息,接收端就可以根据这些信息识别出消息的边界,从而区分出每个消息。
常见的方法有
加入特殊标志
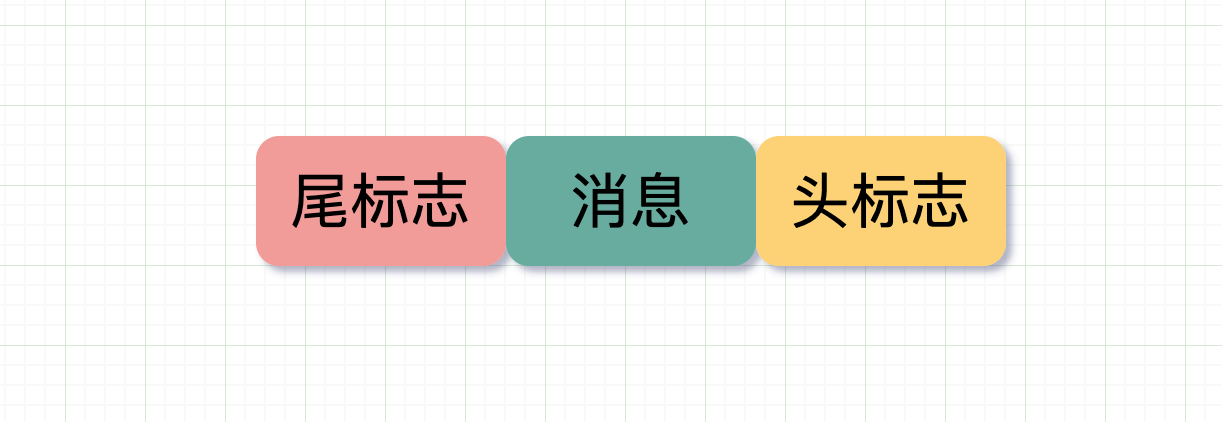
消息边界头尾标志 可以通过特殊的标志作为头尾,比如当收到了
0xfffffe或者回车符,则认为收到了新消息的头,此时继续取数据,直到收到下一个头标志0xfffffe或者尾部标记,才认为是一个完整消息。类似的像 HTTP 协议里当使用 chunked 编码 传输时,使用若干个 chunk 组成消息,最后由一个标明长度为 0 的 chunk 结束。加入消息长度信息
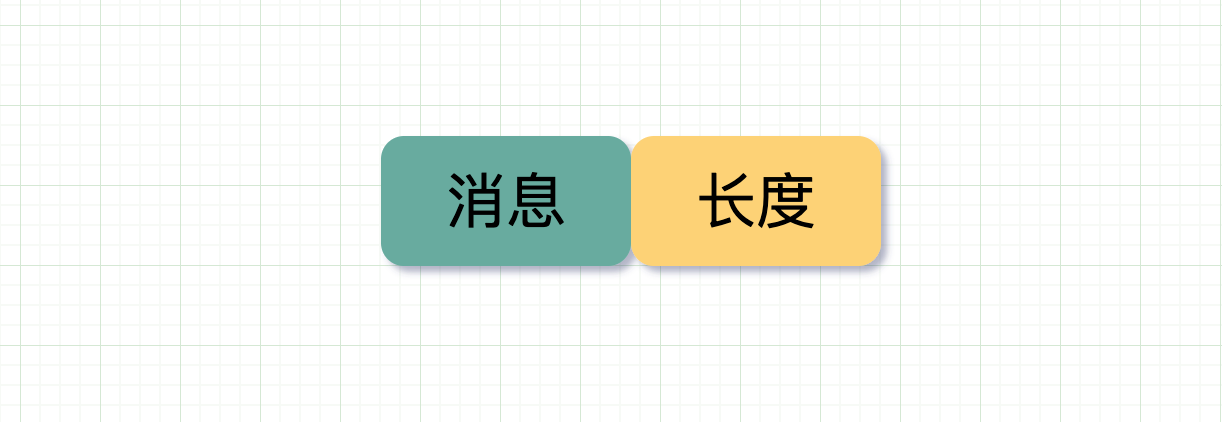
这个一般配合上面的特殊标志一起使用,在收到头标志时,里面还可以带上消息长度,以此表明在这之后多少 byte 都是属于这个消息的。如果在这之后正好有符合长度的 byte,则取走,作为一个完整消息给应用层使用。在实际场景中,HTTP 中的Content-Length就起了类似的作用,当接收端收到的消息长度小于 Content-Length 时,说明还有些消息没收到。那接收端会一直等,直到拿够了消息或超时,关于这一点上一篇文章里有更详细的说明。

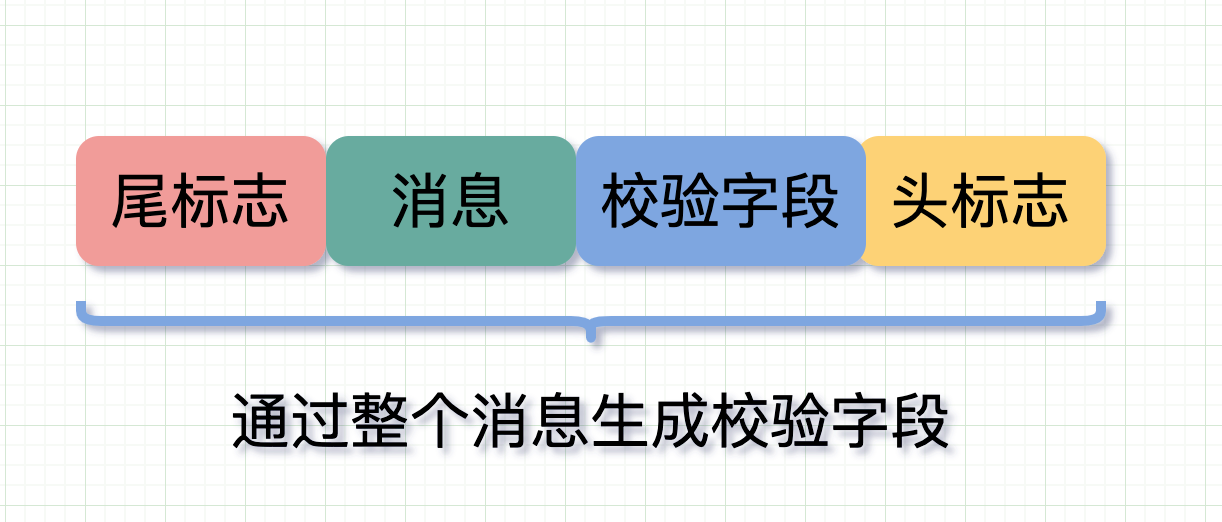
可能这时候会有朋友会问,采用0xfffffe标志位,用来标志一个数据包的开头,你就不怕你发的某个数据里正好有这个内容吗?

是的,怕,所以一般除了这个标志位,发送端在发送时还会加入各种校验字段(校验和或者对整段完整数据进行 CRC 之后获得的数据)放在标志位后面,在接收端拿到整段数据后校验下确保它就是发送端发来的完整数据。
UDP 会粘包吗
跟 TCP 同为传输层的另一个协议,UDP,User Datagram Protocol。用户数据包协议,是面向无连接,不可靠的,基于数据报的传输层通信协议。
基于数据报是指无论应用层交给 UDP 多长的报文,UDP 都照样发送,即一次发送一个报文。至于如果数据包太长,需要分片,那也是 IP 层的事情,大不了效率低一些。UDP 对应用层交下来的报文,既不合并,也不拆分,而是保留这些报文的边界。而接收方在接收数据报的时候,也不会像面对 TCP 无穷无尽的二进制流那样不清楚啥时候能结束。正因为基于数据报和基于字节流的差异,TCP 发送端发 10 次字节流数据,而这时候接收端可以分 100 次去取数据,每次取数据的长度可以根据处理能力作调整;但 UDP 发送端发了 10 次数据报,那接收端就要在 10 次收完,且发了多少,就取多少,确保每次都是一个完整的数据报。
我们先看下IP 报头
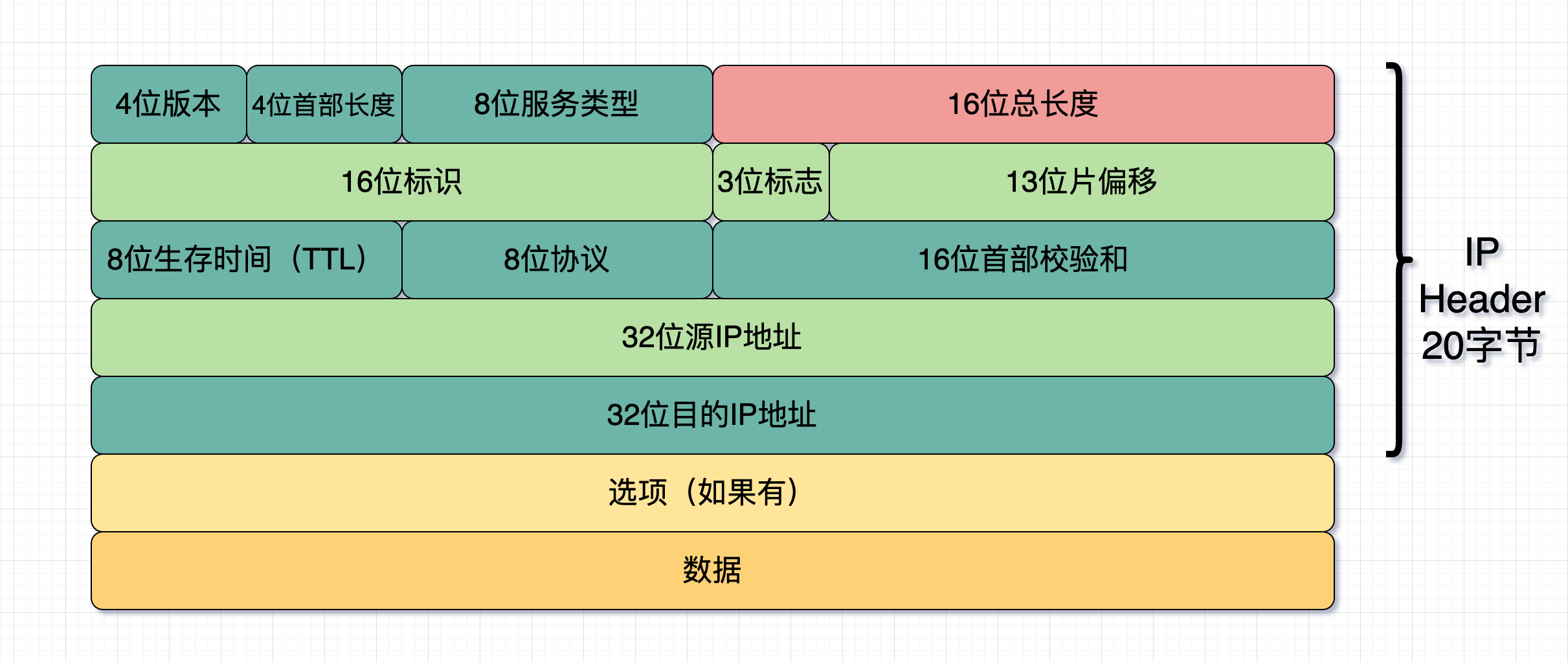
注意这里面是有一个 16 位的总长度的,意味着 IP 报头里记录了整个 IP 包的总长度。接着我们再看下 UDP 的报头。
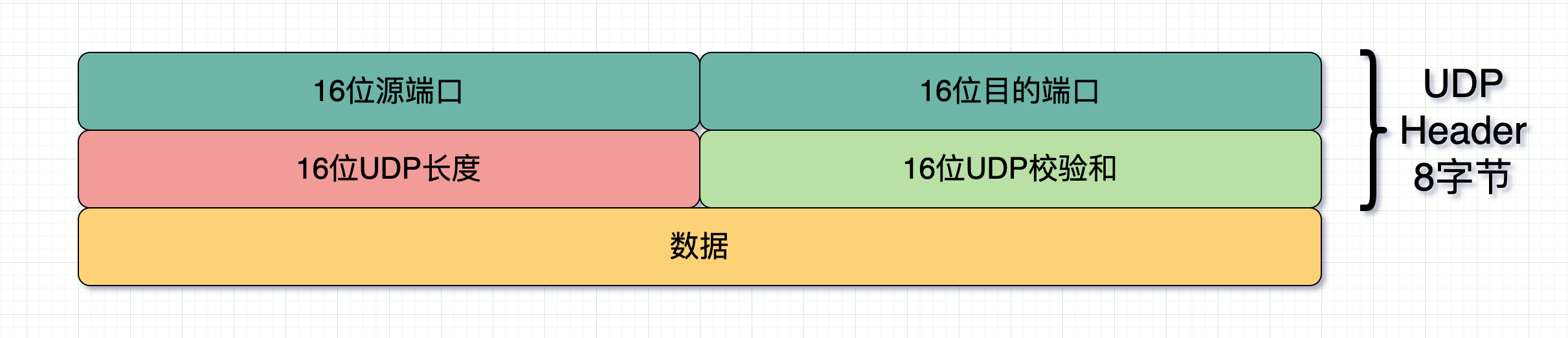
在报头中有16bit用于指示 UDP 数据报文的长度,假设这个长度是 n ,以此作为数据边界。因此在接收端的应用层能清晰地将不同的数据报文区分开,从报头开始取 n 位,就是一个完整的数据报,从而避免粘包和拆包的问题。
当然,就算没有这个位(16 位 UDP 长度),因为 IP 的头部已经包含了数据的总长度信息,此时如果 IP 包(网络层)里放的数据使用的协议是 UDP(传输层),那么这个总长度其实就包含了 UDP 的头部和 UDP 的数据。
因为 UDP 的头部长度固定为 8 字节( 1 字节= 8 位,8 字节= 64 位,上图中除了数据和选项以外的部分),那么这样就很容易的算出 UDP 的数据的长度了。因此说 UDP 的长度信息其实是冗余的。
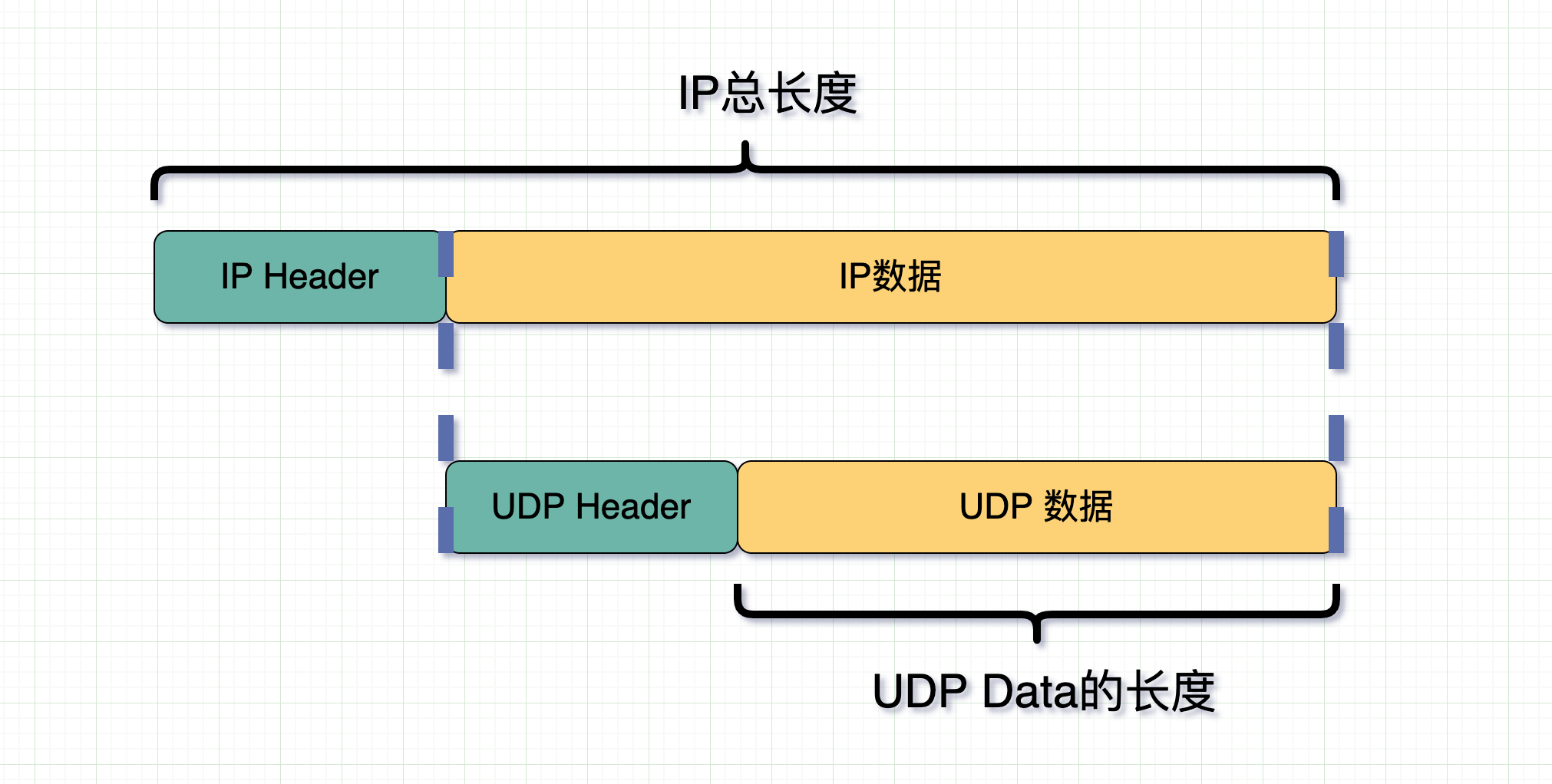
UDP Data 的长度 = IP 总长度 - IP Header 长度 - UDP Header 长度

可以再来看下 TCP 的报头
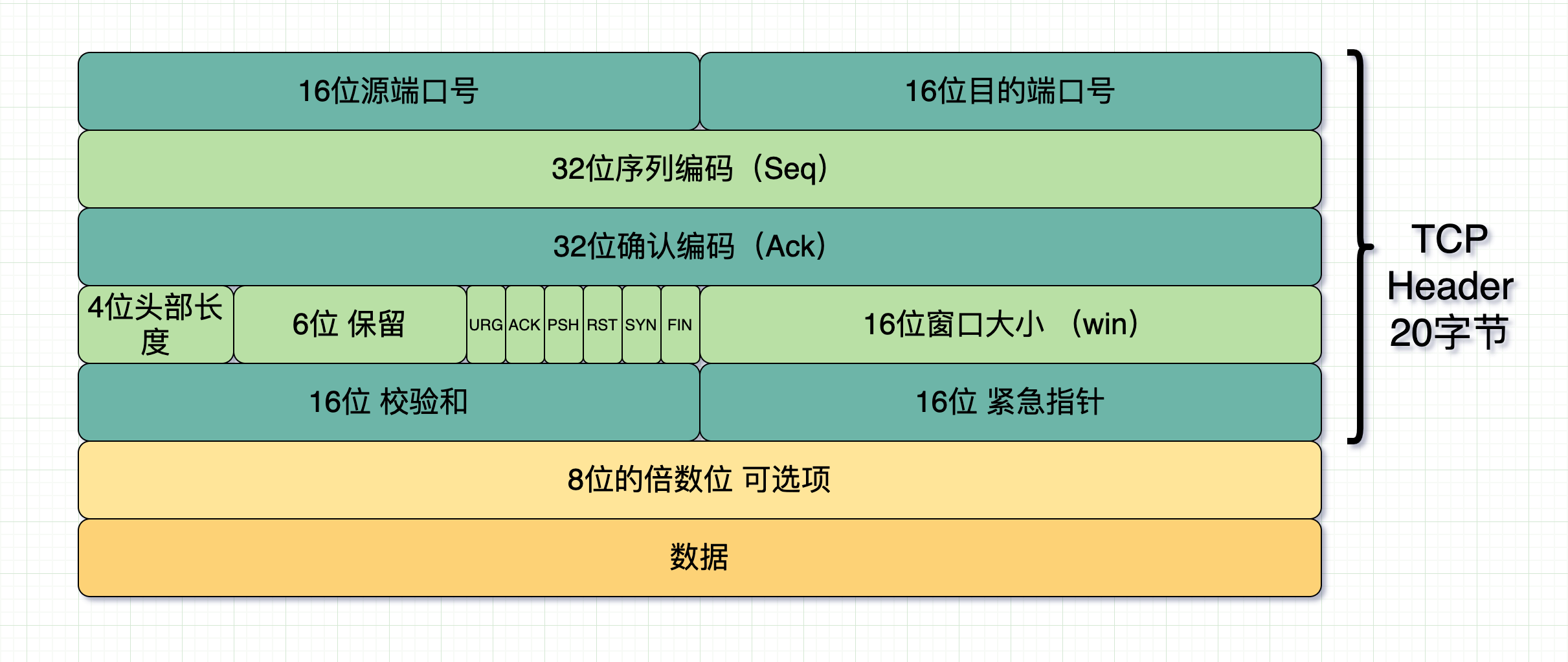
TCP 首部里是没有长度这个信息的,跟 UDP 类似,同样可以通过下面的公式获得当前包的 TCP 数据长度。
TCP Data 的长度 = IP 总长度 - IP Header 长度 - TCP Header 长度。

跟 UDP 不同在于,TCP 发送端在发的时候就不保证发的是一个完整的数据报,仅仅看成一连串无结构的字节流,这串字节流在接收端收到时哪怕知道长度也没用,因为它很可能只是某个完整消息的一部分。
为什么长度字段冗余还要加到 UDP 首部中
关于这一点,查了很多资料,《 TCP-IP 详解(卷2)》里说可能是因为要用于计算校验和。也有的说是因为 UDP 底层使用的可以不是 IP 协议,毕竟 IP 头里带了总长度,正好可以用于计算 UDP 数据的长度,万一 UDP 的底层不是 IP 层协议,而是其他网络层协议,就不能继续这么计算了。
但我觉得,最重要的原因是,IP 层是网络层的,而 UDP 是传输层的,到了传输层,数据包就已经不存在 IP 头信息了,那么此时的 UDP 数据会被放在 UDP 的 Socket Buffer 中。当应用层来不及取这个 UDP 数据报,那么两个数据报在数据层面其实都是一堆 01 串。此时读取第一个数据报的时候,会先读取到 UDP 头部,如果这时候 UDP 头不含 UDP 长度信息,那么应用层应该取多少数据才算完整的一个数据报呢?
因此 UDP 头的这个长度其实跟 TCP 为了防止粘包而在消息体里加入的边界信息是起一样的作用的。
面试的时候咱就把这些全说出去,显得咱好像经过了深深的思考一样,面试官可能会觉得咱特别爱思考,加分加分。
如果我说错了,请把我的这篇文章转发给更多的人,让大家记住这个满嘴胡话的人,在关注之后狠狠的私信骂我,拜托了!

IP 层有粘包问题吗
IP 层会对大包进行切片,是不是也有粘包问题?
先说结论,不会。首先前文提到了,粘包其实是由于使用者无法正确区分消息边界导致的一个问题。
先看看 IP 层的切片分包是怎么回事。
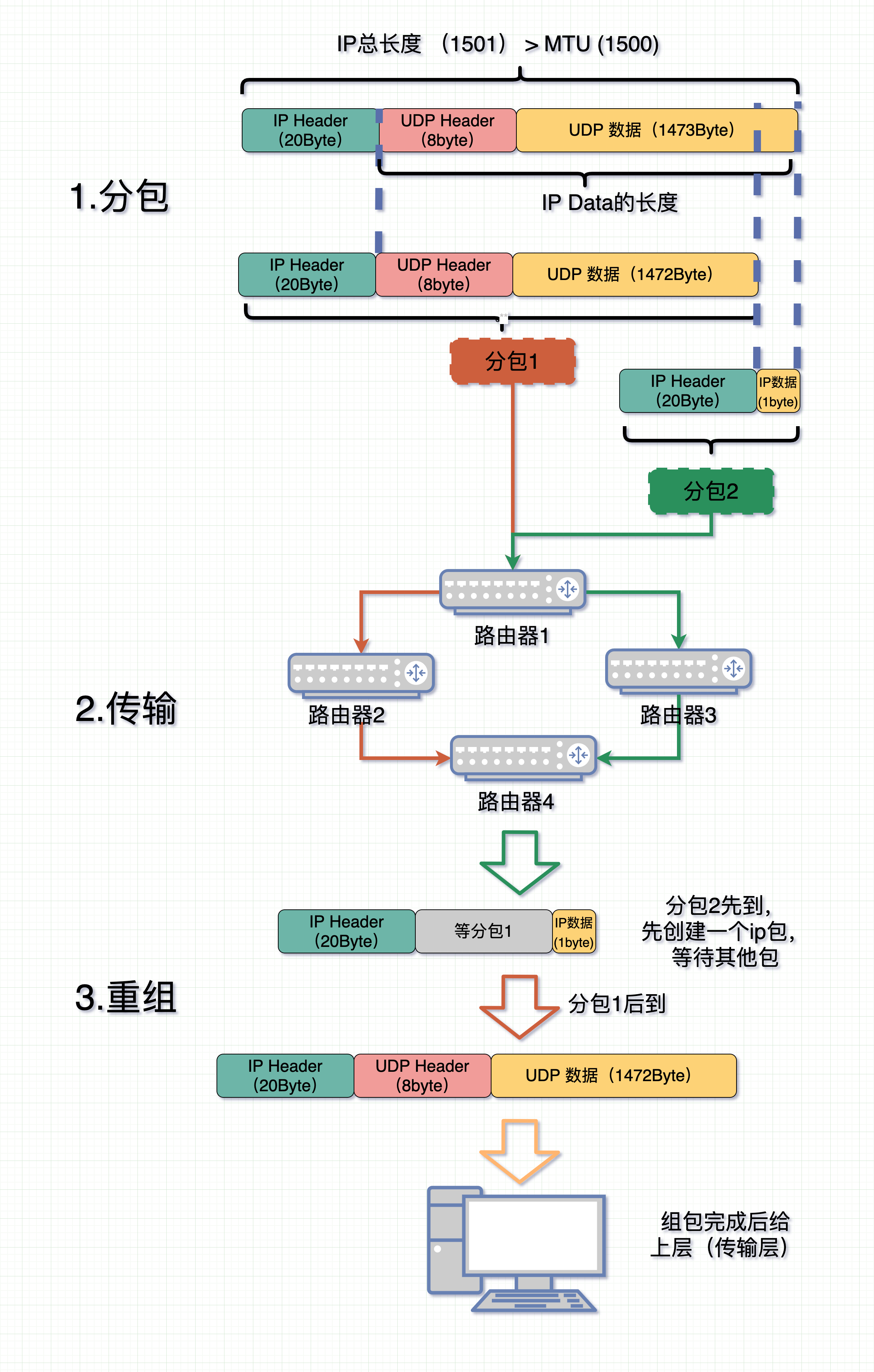
如果消息过长,
IP层会按 MTU 长度把消息分成 N 个切片,每个切片带有自身在包里的位置(offset)和同样的 IP 头信息。各个切片在网络中进行传输。每个数据包切片可以在不同的路由中流转,然后在最后的终点汇合后再组装。
在接收端收到第一个切片包时会申请一块新内存,创建 IP 包的数据结构,等待其他切片分包数据到位。
等消息全部到位后就把整个消息包给到上层(传输层)进行处理。
可以看出整个过程,IP 层从按长度切片到把切片组装成一个数据包的过程中,都只管运输,都不需要在意消息的边界和内容,都不在意消息内容了,那就不会有粘包一说了。
IP 层表示:我只管把发送端给我的数据传到接收端就完了,我也不了解里头放了啥东西。
听起来就像 “我不管产品的需求傻不傻 X,我实现了就行,我不问,也懒得争了”,这思路值得每一位优秀的划水程序员学习,respect。
总结
粘包这个问题的根因是由于开发人员没有正确理解 TCP 面向字节流的数据传输方式,本身并不是 TCP 的问题,是开发者的问题。
- TCP 不管发送端要发什么,都基于字节流把数据发到接收端。这个字节流里可能包含上一次想要发的数据的部分信息。接收端根据需要在消息里加上识别消息边界的信息。不加就可能出现粘包问题。
- TCP 粘包跟 Nagle 算法有关系,但关闭 Nagle 算法并不解决粘包问题。
- UDP 是基于数据报的传输协议,不会有粘包问题。
- IP 层也切片,但是因为不关心消息里有啥,因此有不会有粘包问题。
TCP发送端可以发10 次字节流数据,接收端可以分100 次去取;UDP发送端发了10 次数据报,那接收端就要在10 次收完。
数据包也只是按着 TCP 的方式进行组装和拆分,如果数据包有错,那数据包也只是犯了每个数据包都会犯的错而已。
最后,李东工作没了,而小白表示

文章推荐:
别说了,一起在知识的海洋里呛水吧
关注公众号:【小白 debug】