golang 高性能无 GC 的缓存库 bigcache 是怎么实现的?
golang 高性能无 GC 的缓存库 bigcache 是怎么实现的?
我们写代码的时候,经常会需要从数据库里读取一些数据,比如配置信息或者诸如每周热点商品之类的数据。
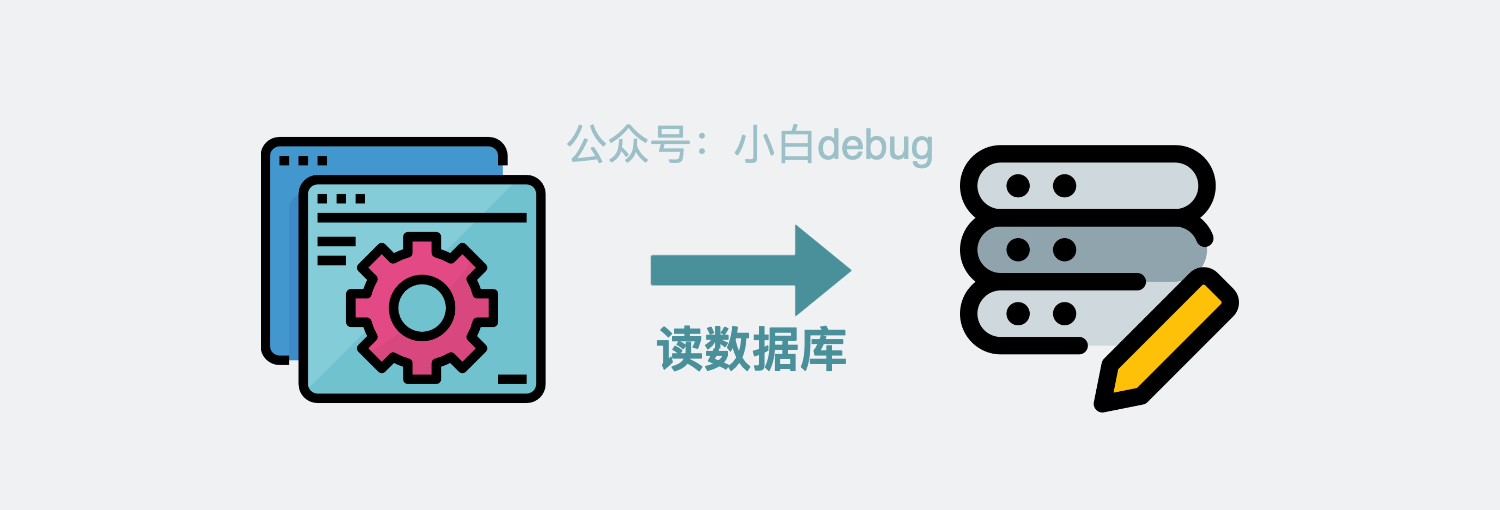
如果这些数据既不经常变化,又需要频繁读取,那比起每次都去读数据库,更优的解决方案就是将它们放到应用的本地内存里,这样可以省下不少数据库 IO,性能嘎一下就上来了。
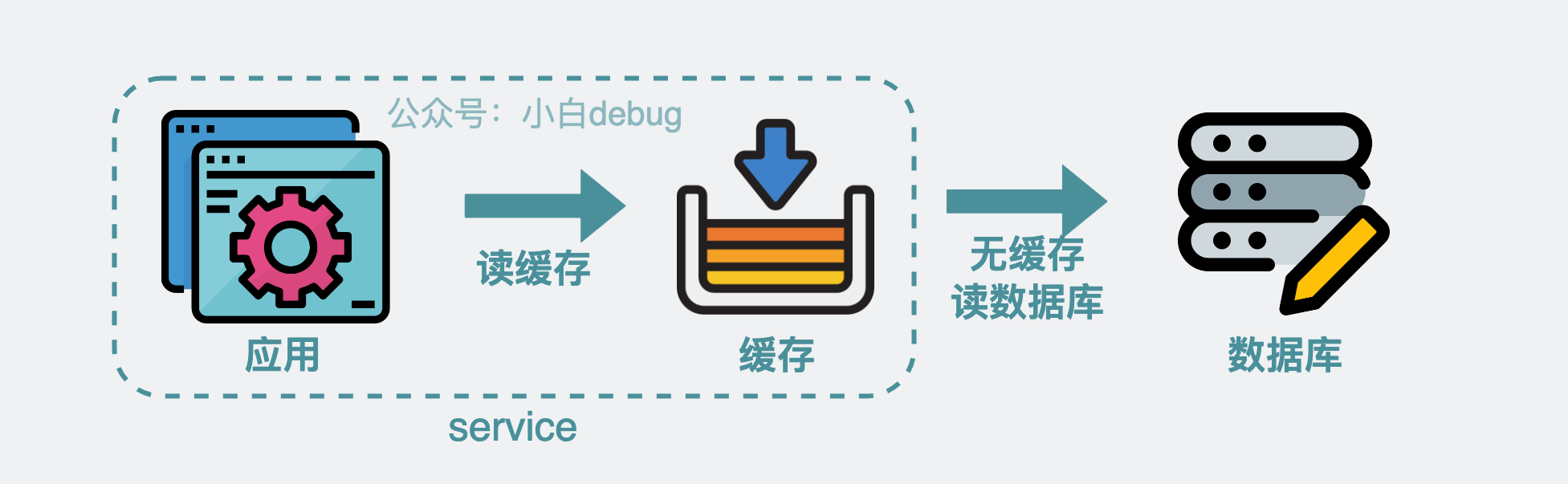
那么现在问题就来了,假设我要在某个服务应用里实现一个缓存组件去存各种类型的数据,该怎么实现这个组件呢?
从一个 map 说起
最简单的的方案就是使用 map,也就是字典,将需要保存的结构以 key-value 的形式,保存到内存中。比如系统配置,key 就叫 system_config,value 就是具体的配置内容。 需要读取数据就用 v = m[key]来获取数据,需要写数据就执行m[key] = v.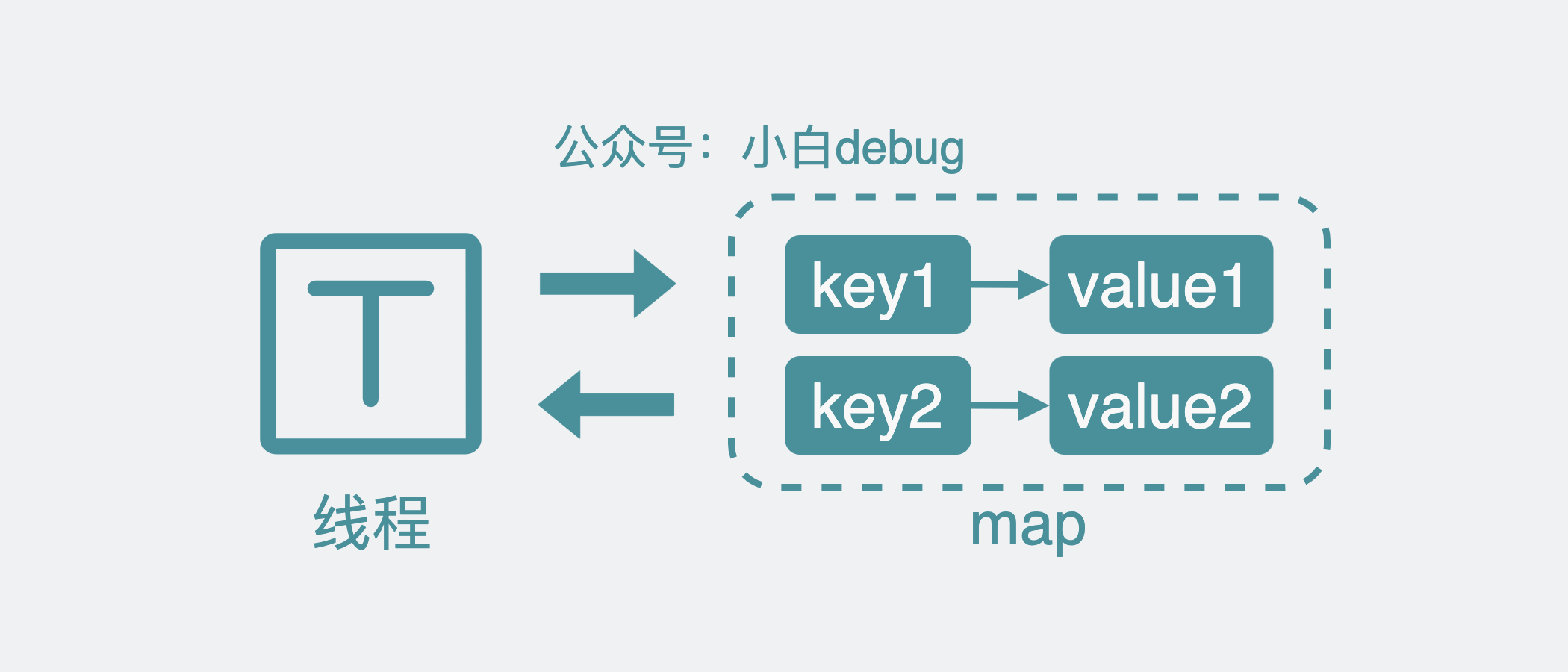
这样看起来在单线程下是满足需求了。
但如果我想在多个线程(协程)里并发读写这个缓存呢?
那必然会发生竞态问题。
这就需要加个读写锁了。读操作前后要加锁和解锁,也就是改成下面这样。
RLock()
v = m[key]
RUnLock()
写操作也需要相应修改:
Lock()
m[key] = v
UnLock()
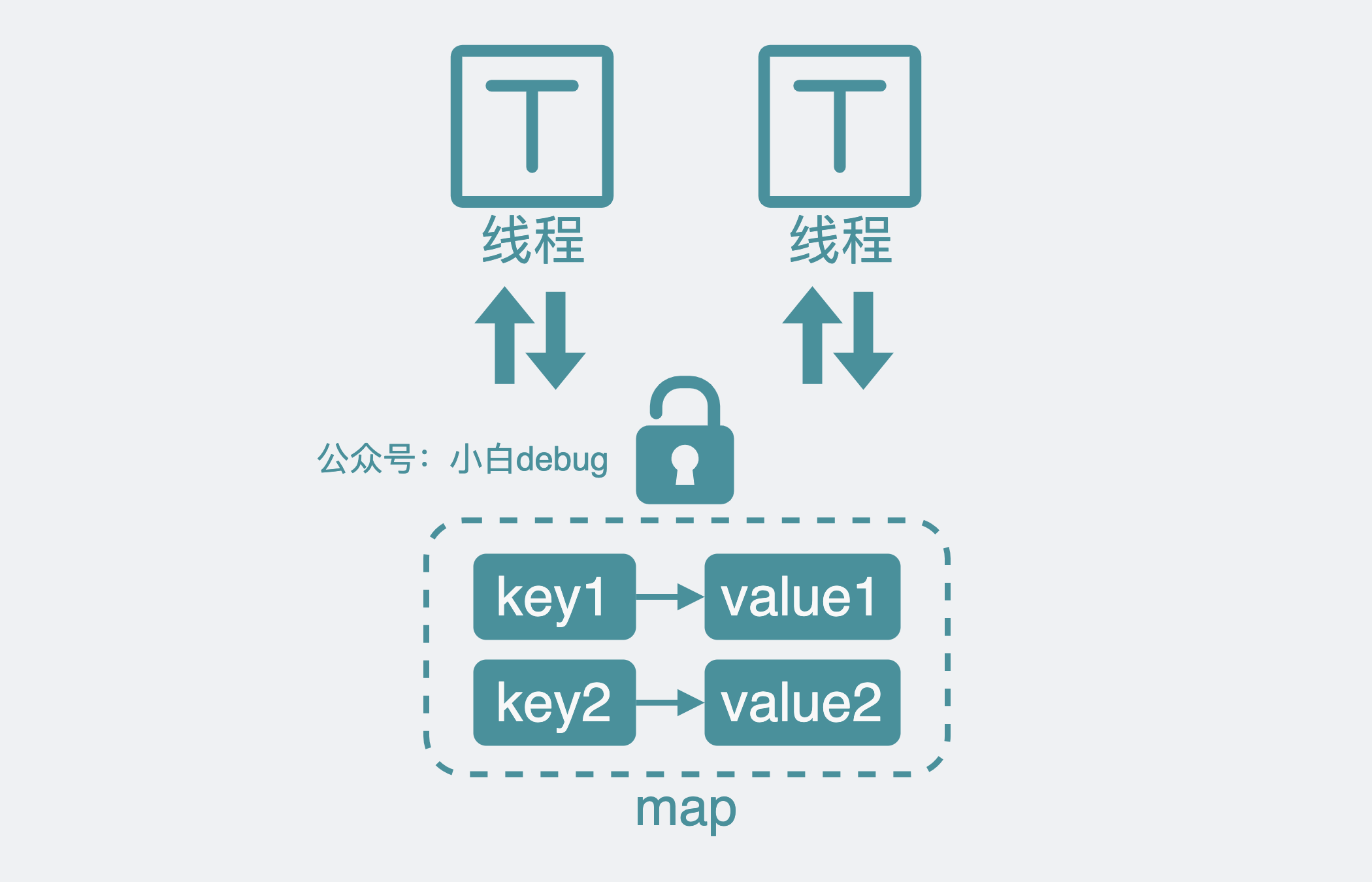
这在读写不频繁的场景下是完全 ok 的,如果没有什么性能要求,服务也没出现什么瓶颈,就算新来的实习生笑它很 low,你也要有自信,这就是个好用的缓存组件。
架构就是这样,能快速满足需求,不出错就行。
但其实这个方案其实也有很大的问题,如果读写 qps 非常高,那么就会有一堆请求争抢同一个 map 锁,这对性能影响太大了。
怎么解决呢?
将锁粒度变小
上面的方案中,最大的问题是所有读写请求,都抢的同一个锁,所以竞争才大,如果能将一部分请求改为抢 A 锁,另一部分请求改为抢 B 锁,那竞争就变小了。
于是,我们可以将原来的一个 map,进行分片,变成多个 map,每个 map 都有自己的锁。
发生读写操作时,第一步先对 key 进行 hash 分片,获取分片对应的锁后,再对分片 map 进行读写。
只有落在同一个分片的请求才会发生锁争抢。也就是说 map 拆的越细,锁竞争就越小。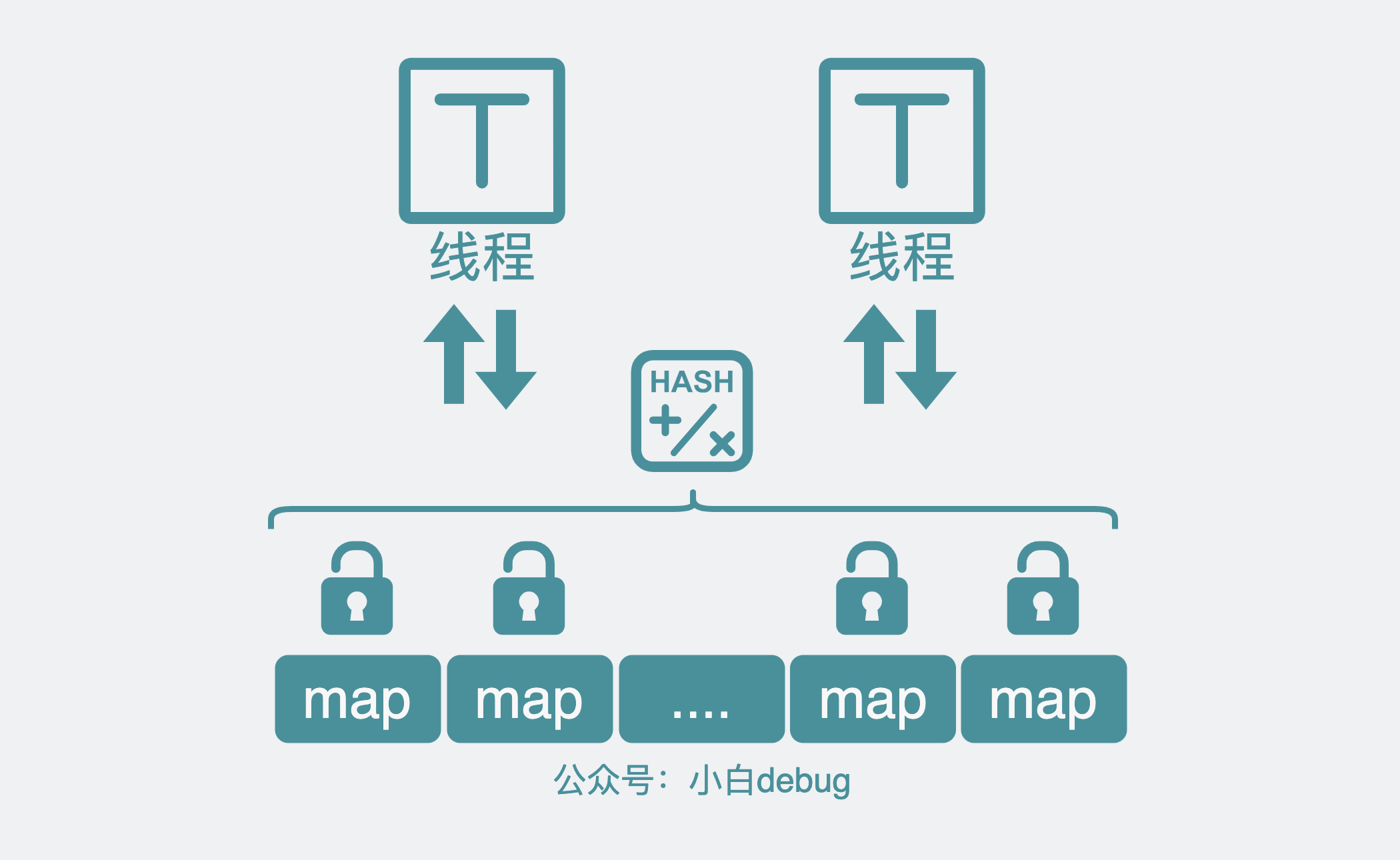
像这种将资源分割成多个独立的分片(segments/shard),每个段都有一个对应的锁来控制并发访问的控制机制, 其实就是所谓的分片(段)锁。
看起来很完美,但其实还有问题。
gc 带来的问题
像 C/C++这类语言中,用户申请的内存需要由用户自己写代码去释放,一不小心忘了释放那就会发生内存泄露,给程序员带来了很大的心智负担。
为了避免这样的问题,一般高级语言里都会自带 GC,也就是垃圾回收(Garbage Collection),说白了就是程序员只管申请内存,用完了系统会自动回收释放这些内存。
比如 golang,它会每隔一段时间就去扫描哪些变量内存是可以被回收的。对于指针类型,golang 会先扫指针,再扫描指针指向的对象里的内容。
map 缓存里放的东西少还好说,缓存里的 key-value 一多,那就喜提多遍疯狂扫描,浪费,全是浪费,golang 你糊涂啊。
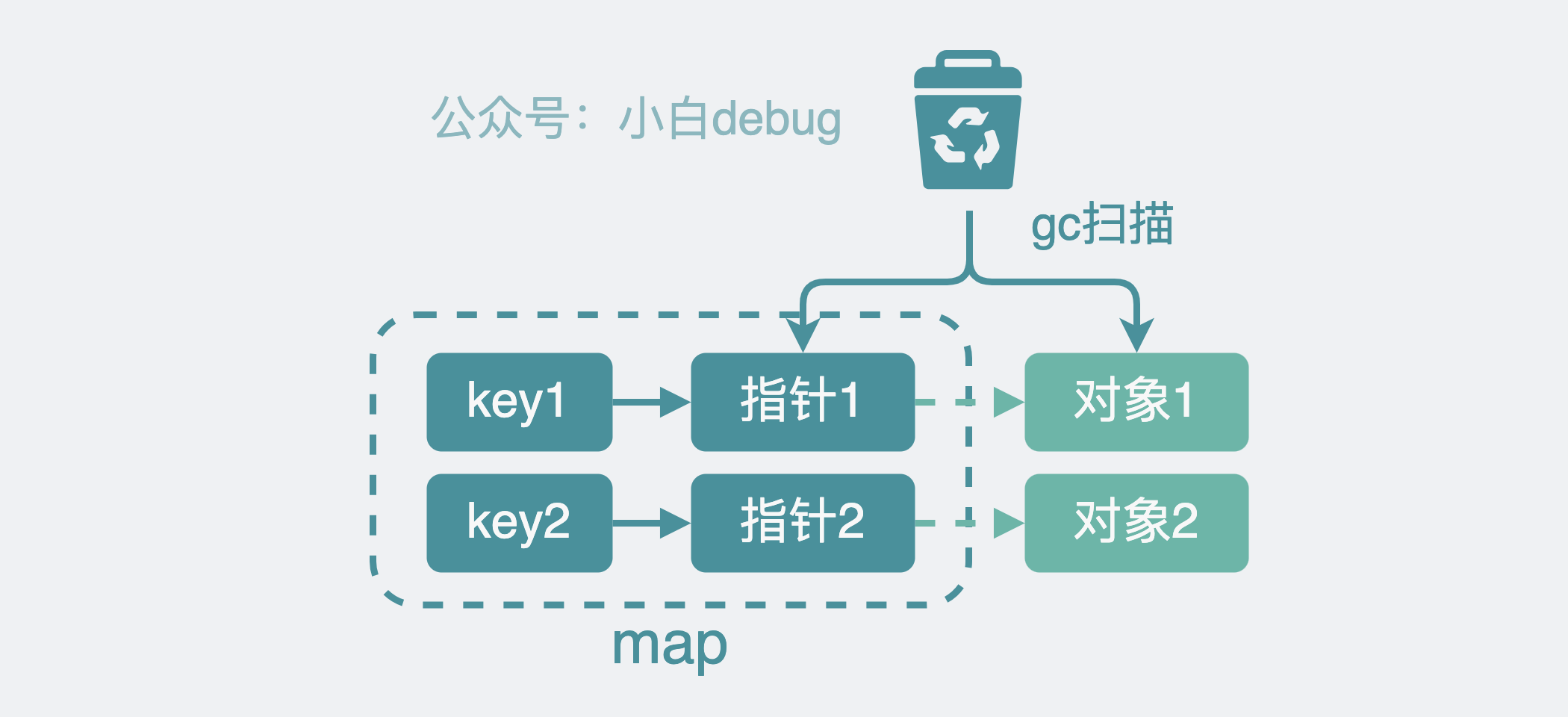
那有没有办法可以减少这部分 gc 扫描 成本呢?
有。golang 对于 key 和 value 都不含指针的的 map,会选择跳过,不进行 gc 扫描。
所以我们需要想办法将 map 里的内容改成完全不含指针。
原来 map 中放的 key-value,key 和 value 都可能是指针结构体。
对于 key
原来 key 是用的字符串,在 golang 中字符串本质上也是指针,于是我们将它进行 hash 操作,将字符串转为整形。信息经过 hash 操作后,有可能会丢掉部分信息,为了避免hash 冲突时分不清具体是哪个 key-value,我们会将 key 放到 value 中一起处理,继续看下面。
对于 value
我们可以构造一个超大的 byte 数组 buf,将原来的 key value 等信息经过序列化,变成二进制 01 串。将它存放到这个超大 buf 中,并记录它在 超大 buf 中的位置 index。
然后将这个位置 index 信息放到 map 的 value 位置上,也就是从 key-velue,变成了 key-index。
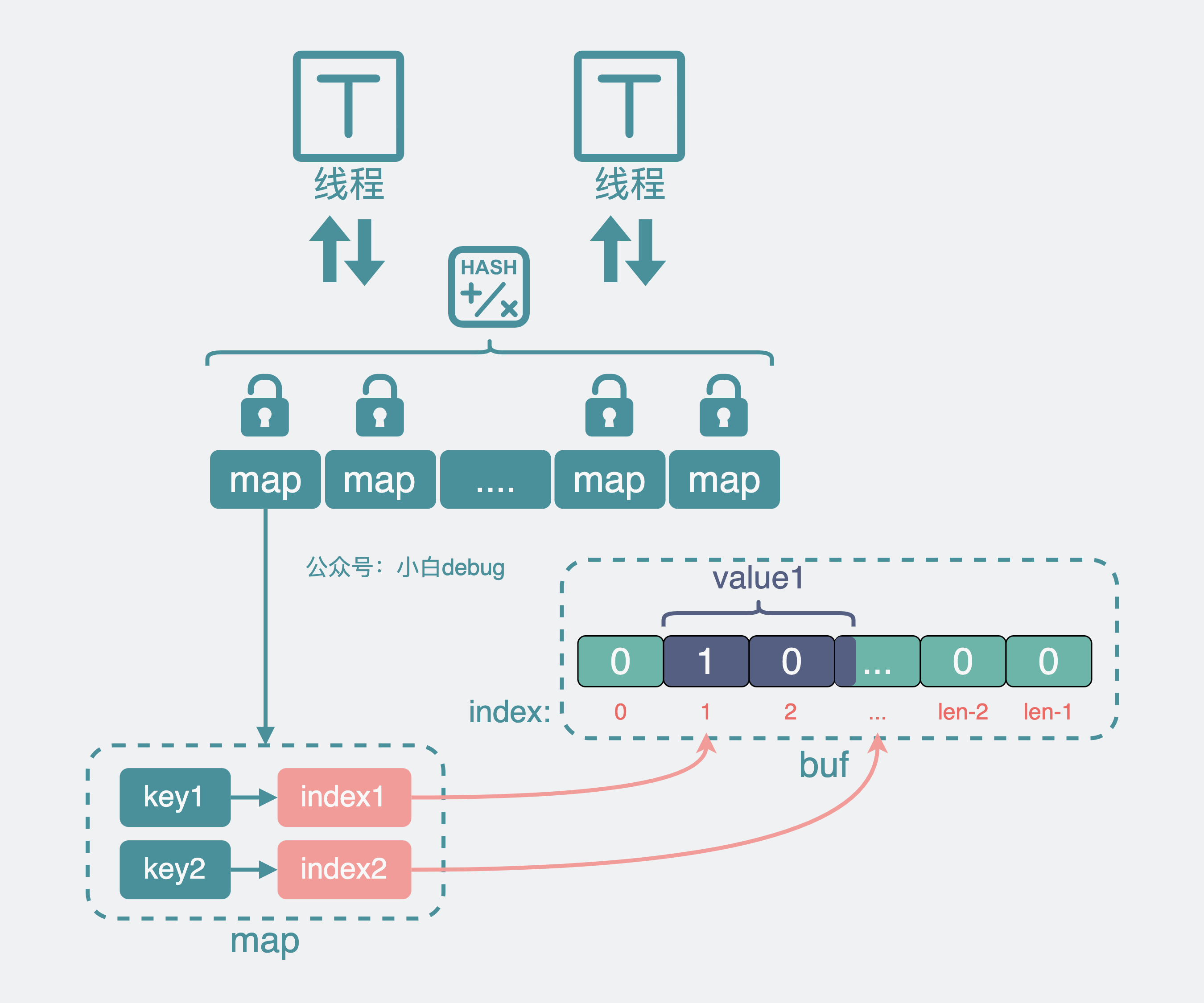
同时为了防止 buf 数组变得过大,占用过多内存导致应用 oom,还可以采用 ringbuf 的结构,写到尾部就重头开始写,如果 ringbuf 空间不够,还能对它进行扩容。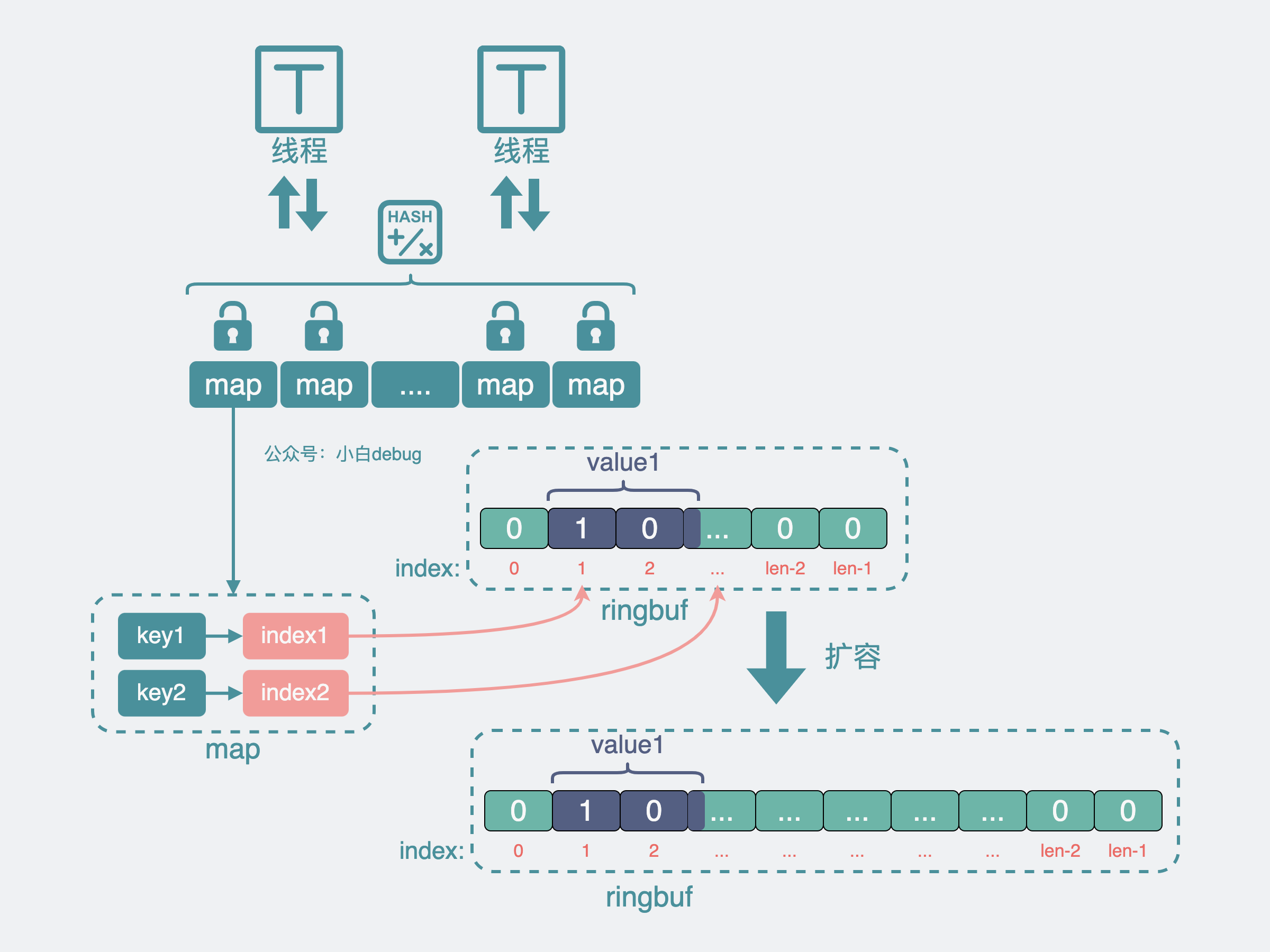
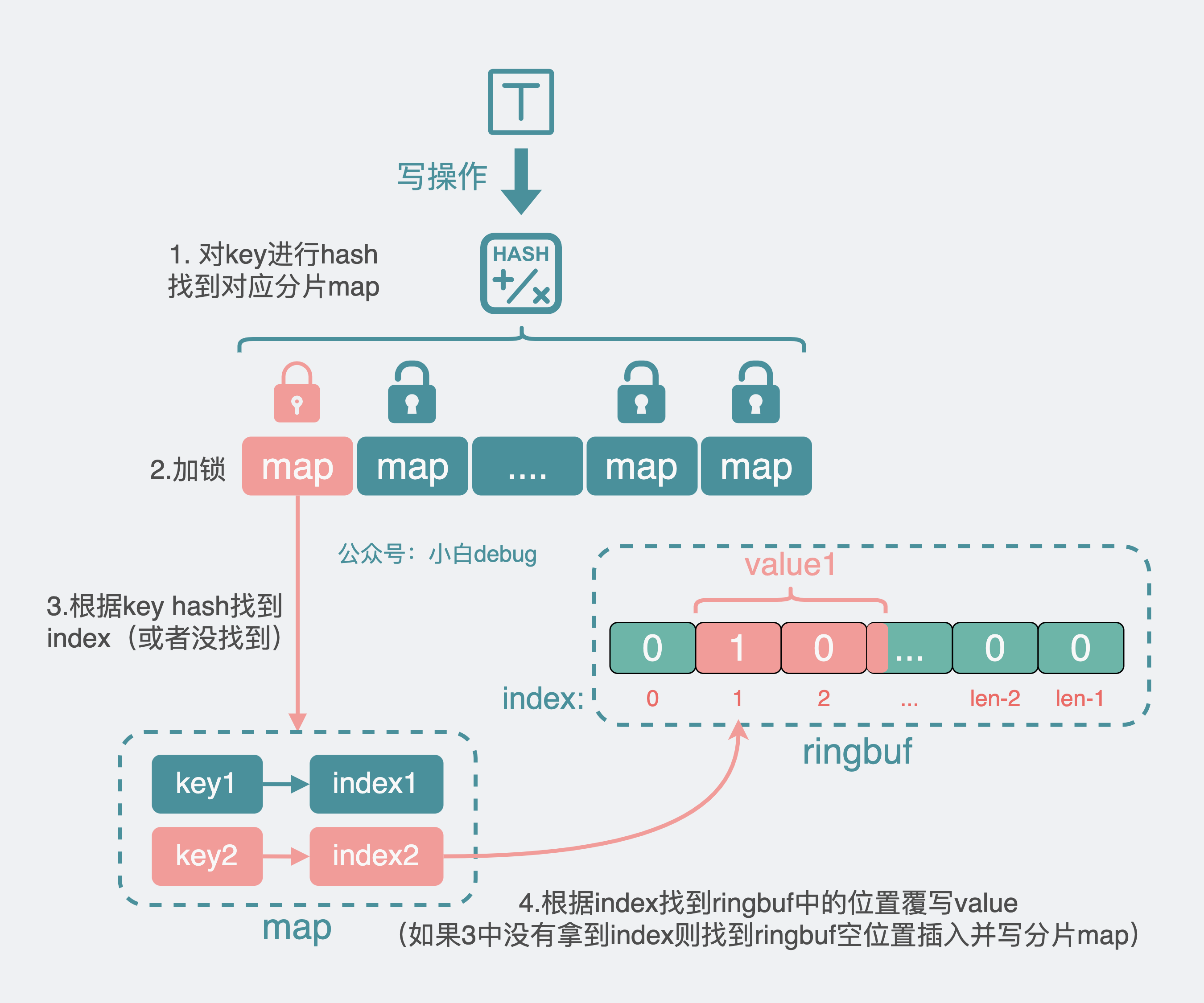
写操作
对于写操作,程序先将 key 进行 hash,得到所在分片 map,加锁。
- 如果不能从分片 map 里拿到 index,也就是 map 中没旧数据,那就找到 ringbuf 里的空位置后写入 value,再将 index 写入 map。
- 如果能从分片 map 里拿到 index,也就是 map 中有旧数据,那就覆盖写 ringbuf。
然后解锁,结束流程。
读操作
对于读操作,程序同样先对 key 进行 hash,得到分片 map。
加锁,从分片 map 里拿到 value 对应的 index,拿着这个 index 到 ringbuf 数组中去获取到 value 的值,然后解锁,结束流程。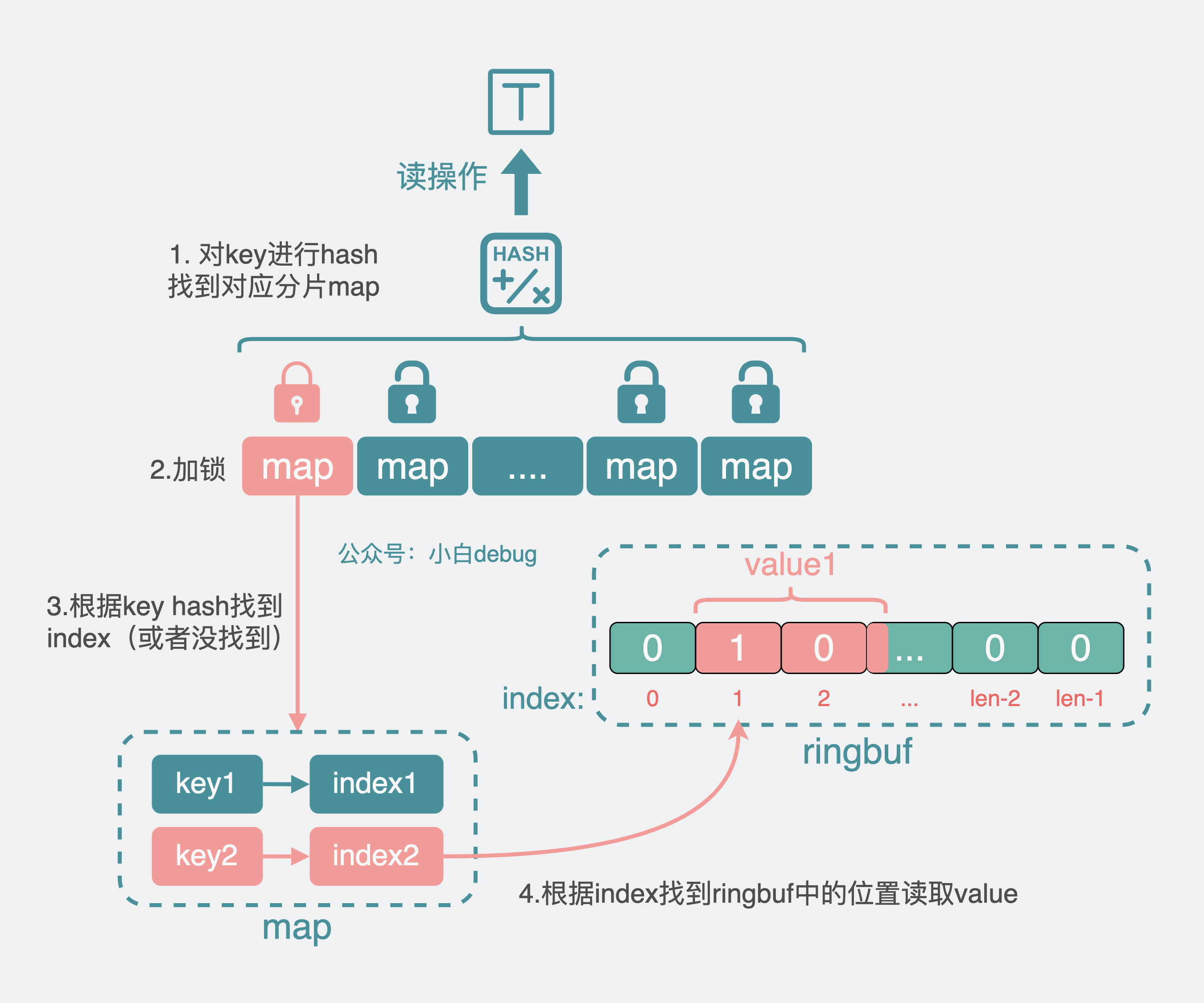
到这里,我们可以发现 map 的 key 和 value 都被改成了整形数字,也就省下了大量的 gc 扫描,大大提升了组件性能。
其实这就是有名的高性能无 GC 的缓存库 github.com/allegro/bigcache 的实现原理。
bigcache 的使用
它的使用方法大概像下面这样。
package main
import (
"fmt"
"github.com/allegro/bigcache/v3"
)
func main() {
// 设置 bigcache 配置参数
cacheConfig := bigcache.Config{
Shards: 1024, // 分片数量,提高并发性
}
// 初始化 bigcache
cache, _ := bigcache.NewBigCache(cacheConfig)
// 写缓存数据
key := "欢迎关注"
value := []byte("小白debug")
cache.Set(key, value)
// 读缓存数据
entry, _ := cache.Get(key)
fmt.Printf("Entry: %s\n", entry)
}
说白了就是 Get 方法读缓存数据,Set 方法写缓存数据,比较简单。
现在,大概原理和使用方法我们都懂了,我们再来看下 bigcache 中,两个我认为挺巧妙的设计点。
ringbuf 中的数据格式
在前面的介绍中,我猜你心里可能有疑问,程序从 ringbuf 读写 value 的时候,ringbuf 里面放的都是 01 二进制数组,程序怎么知道该读多少 bit 才算一个完整 value?
bigcache 的解法非常值得学习,它重新定义了一个新的数据格式。
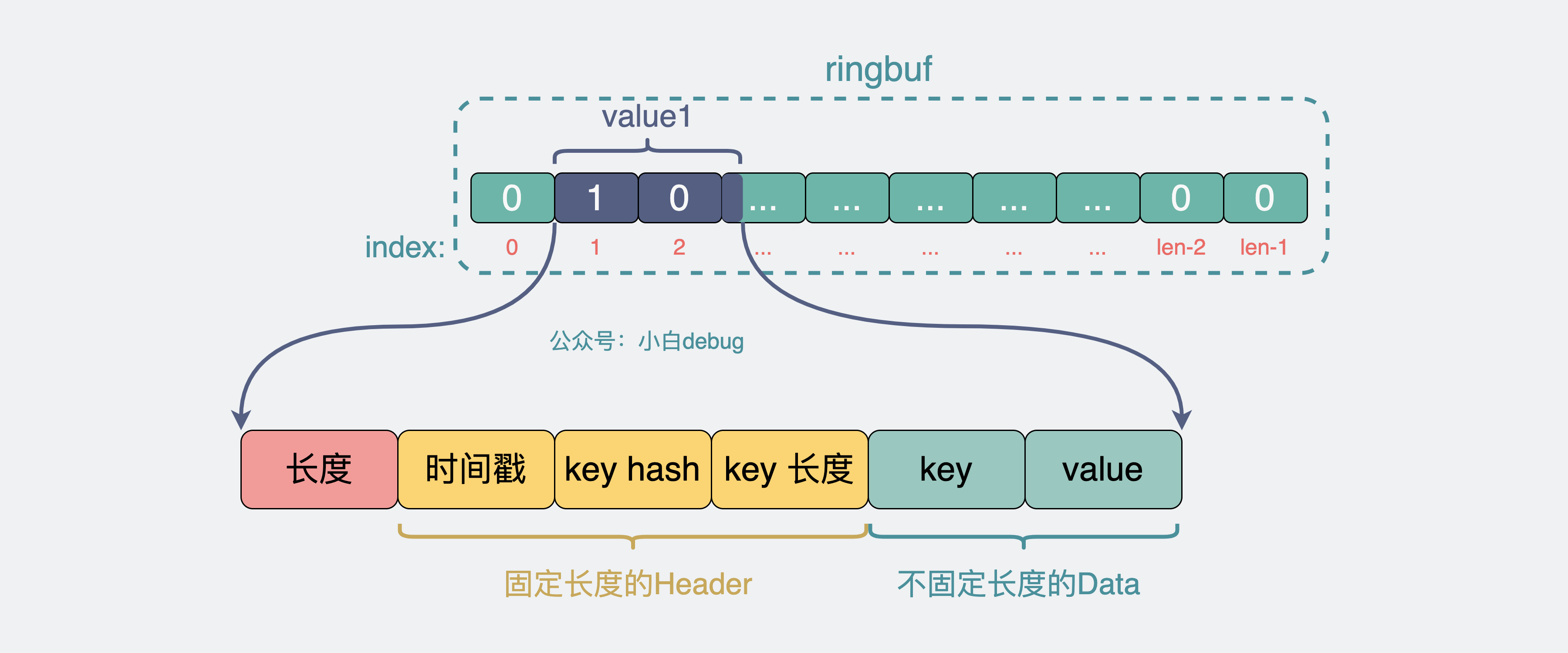
length 表示 header 到 data 的数据长度
header 是固定长度
data 则是 key 和 value 的完整数据。
当读取 ringbuf 时,我们会先读到 length,有了它,我们就能在 ringbuf 里拿到 header 和 data,header 里又含有 key 的长度,这样就能在 data 里将 key 和 value 完整区分开来。
很多网络传输框架中都会用到类似的方案,后面有机会跟大家细聊。
ringbuffer 的第 0 位
另外,还有个巧妙的设计是,在 bigcache 中, ringbuffer 的第 0 位并不用来存放任何数据,这样如果发现 分片 map 中得到数据的 index 为 0,就可以直接认为没有对应的缓存数据,那就不需要跑到 ringbuffer 里去捞一遍数据了,觉得学到了,记得在右下角给我点个赞。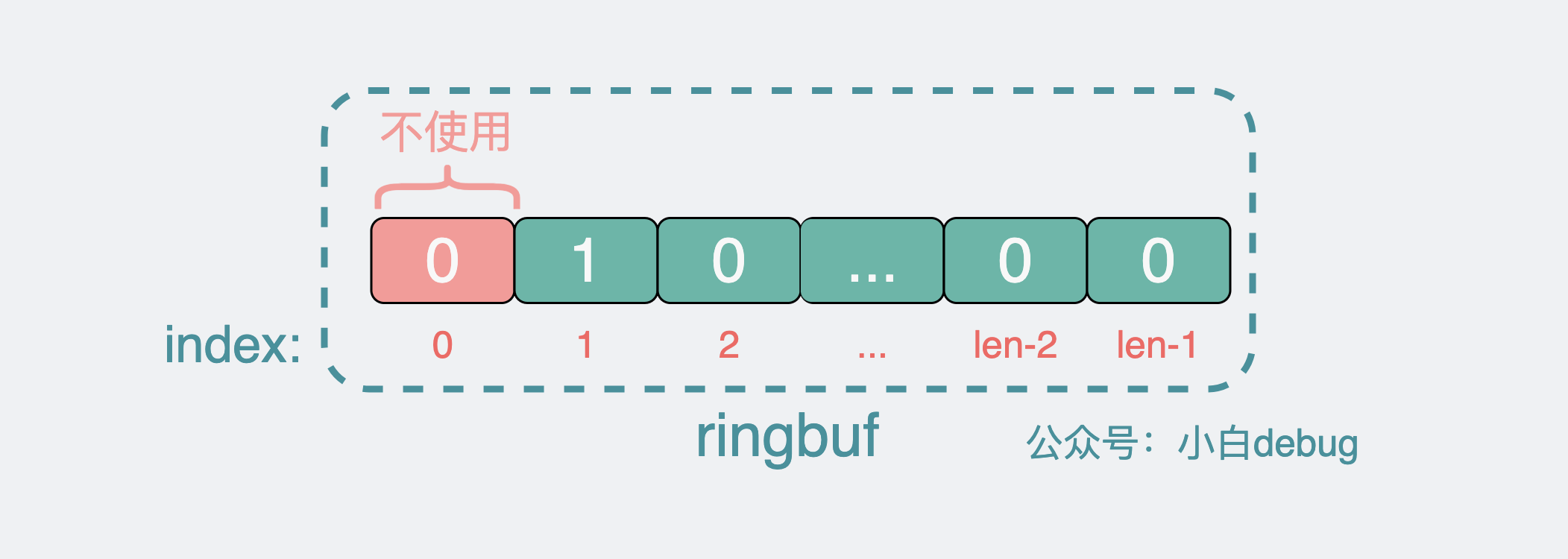
bigcache 的缺点
bigcache 性能非常好,但也不是完全没有问题。比较明显的是,它读写数据时,用的都是byte 数组,但我们平时写代码用的都是结构体,为了让结构体和 byte 数组互转,我们就需要用到序列化和反序列化,这些都是成本。
另外它的缓存淘汰策略也比较粗暴,用的是 FIFO,不支持 LRU 或 LFU 的淘汰策略。
总结
- 对于不频繁读写的场景,加锁读写 map 就够了。
- 对于需要频繁读写的场景,可以使用分片锁,减少锁竞争。
- 对于 golang,map 中含指针的话会引发 gc 扫描,为了降低这部分成本,引入了 ringbuf,map 的 value 则改为缓存对象在 ringbuf 中的 index,以此提升组件性能。以后面试官问你看没看过哪些优秀组件的源码的时候,你知道该怎么回答了吧?
最后
不管是空间换时间还是时间换空间,适合、够用,就是最好的,架构总是在做折中。
这就像我们做的 go/java 后端训练营,你不能要求它效果好,又要求它价格低。
不管你是学生,还是工作了几年的程序员,如果你最近想换份工作,又对自己的实力不自信,可以考虑下我们训练营。